APIで最小ループを組むと、プロンプト改善ではなく停止条件の設計になる
生成、評価、フィードバック、再生成を分けた最小ループを検証用スクリプトで実装し、AI出力を安定させるときに見るべき停止条件と評価単位を整理します。

前回は、AIの出力を一発指示で当てにいくのではなく、生成、評価、フィードバック、再生成のループで扱う考え方を整理しました。
LLM Lab プロンプトを磨いても安定しないので、ループで回すことにした 生成、評価、フィードバック、再生成のループでAI出力を改善する考え方と、手動で始める最小ステップを整理しています。 https://llm-lab.dev/posts/llm-loop-engineering-first-step/
今回は、その考え方をAPI実装へ落とす前段として、最小の検証用スクリプトを作りました。外部のLLM APIは呼ばず、生成器はモックにしています。狙いはモデル性能の比較ではなく、ループをコードにした瞬間に何を設計対象として固定しなければならないかを見ることです。
正直、最初は「生成関数を呼んで、ダメならもう一回呼べばよい」くらいに考えていました。でもコードにすると、重要なのは再実行そのものではなく、評価単位、フィードバックの粒度、停止条件でした。
最小ループで確認したかったこと
今回の検証では、問い合わせ返信案のような短い文章生成を題材にしました。実装したのは、記事用に用意した検証スクリプトです。入力タスクに対してモックの生成結果を返し、その出力をルーブリックで評価し、未達項目だけを次の試行へ渡します。
確認したかった設計要素は、次の4つです。
- 生成と評価を別の関数に分ける
- ルーブリックをコード上の判定条件として持つ
- 未達項目だけをフィードバックとして次の生成へ渡す
- 最大試行回数で必ず停止する
ここではLLM APIの呼び出し部分をあえてモックにしました。API呼び出しを入れると、モデル差、認証、レイテンシ、料金、ネットワーク失敗が混ざります。最初に見たいのは、ループ構造そのものが観測できるかどうかです。
生成と評価を分ける
最小構成では、generate() と evaluate() を分けました。実際のAPI実装では、前者が生成用モデル呼び出し、後者が評価用モデル呼び出し、または決定的な検証コードになります。
function generate({ attempt, feedback }) {
// 実運用ではここがLLM API呼び出しになる
}
function evaluate(output) {
const failed = rubric.filter((item) => !item.check(output));
return {
passed: failed.length === 0,
failed
};
}この分離は地味ですが重要です。生成結果の良し悪しを、生成した文脈の中でそのまま判断すると、評価が甘くなりやすいからです。別関数にしておくと、あとから評価だけをLLM-as-judgeに差し替えたり、一部の条件だけを正規表現やスキーマ検証に寄せたりできます。
ルーブリックは文章ではなく運用単位になる
今回のルーブリックは、次の3項目です。
const rubric = [
"最初の段落で結論を述べる",
"次に取る行動を2つ以上書く",
"担当者の役割を明記する"
];実際のスクリプトでは、それぞれに check と feedback を持たせています。ここで大事なのは、ルーブリックを単なる評価文ではなく、運用上の単位として扱うことです。
たとえば「読みやすい文章にする」は、人間の感覚としては分かります。しかしAPIでループを回すときには、何が満たされれば合格なのか、どの条件が未達なら何を返すのかまで落とす必要があります。
ここで止まるのか。プロンプトではなく、評価語彙の粗さで止まる。
この感覚は、実際にコードへ落として初めて強く出ました。
成功ケースのログ
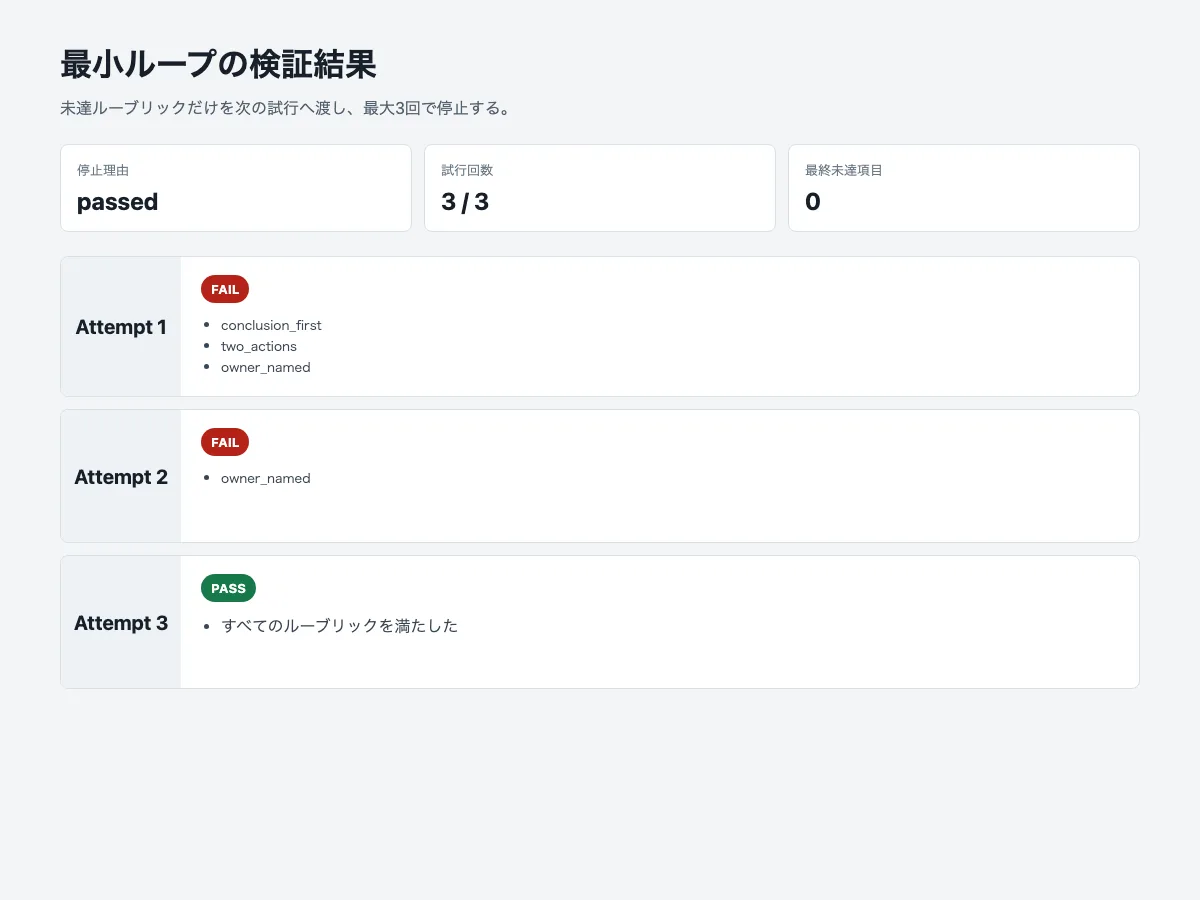
検証用スクリプトは、成功ケースでは3回目の試行で合格します。
{
"task": "問い合わせ返信案を作る",
"mode": "normal",
"maxAttempts": 3,
"stopReason": "passed",
"attempts": [
{
"attempt": 1,
"passed": false,
"failedRubricIds": [
"conclusion_first",
"two_actions",
"owner_named"
]
},
{
"attempt": 2,
"passed": false,
"failedRubricIds": [
"owner_named"
]
},
{
"attempt": 3,
"passed": true,
"failedRubricIds": []
}
]
}このログで見たいのは、最終出力の文章そのものよりも、どの評価項目がどの試行で消えたかです。ループを運用するなら、「よくなった気がする」では足りません。どの条件が未達で、どのフィードバックによって改善したかを追える必要があります。
失敗ケースも同じくらい重要
ループを入れるときに一番危ないのは、改善しない出力を延々と再生成することです。そのため、検証用スクリプトには、あえて改善しないモードも入れました。
npm run verify:stuckこのコマンドは、同じ出力を返し続けるモック生成器を使います。最大3回で停止し、stopReason は max_attempts になります。これは記事用に用意した検証コマンドであり、標準CLIではありません。ループが改善できない場合にも必ず止まることを確認するためのものです。
{
"mode": "stuck",
"maxAttempts": 3,
"stopReason": "max_attempts"
}ここを設計しておかないと、APIコスト、レイテンシ、ユーザー体験のすべてが崩れます。特に業務システムに入れる場合、「不合格なので再実行しました」だけでは不十分です。上限回数に達したら、最終出力と未達項目を人間へ返す、または別の処理にフォールバックする必要があります。
API実装で最初に固定するもの
今回の最小実装から見ると、APIでループを組むときに最初に固定すべきものは、モデル名やプロンプト文よりも次の項目です。
- 何回まで試行するか
- 何を合格条件にするか
- どの未達項目を次の入力へ戻すか
- 合格しなかったときに何を返すか
- ログに何を残し、何を残さないか
モデルの選択やプロンプト改善はもちろん重要です。ただ、ループ設計では、モデルが賢く振る舞うことに期待するだけでは不安定です。モデルが失敗したときに、システムとしてどう扱うかを先に決める必要があります。
LLM APIに差し替えるときの形
今回の generate() はモックですが、実際にはここをLLM API呼び出しに置き換えます。評価も、決定的に見られる項目はコードで判定し、文章品質のような項目は評価用のモデル呼び出しへ寄せる構成が考えられます。
const output = await generateWithModel({
task,
previousFeedback
});
const evaluation = await evaluateWithRubric({
task,
output,
rubric
});このとき、生成用と評価用の呼び出しは分けたほうが扱いやすいです。トレース上でも、生成、評価、再生成が別イベントとして見えるため、どこで失敗しているかを後から追いやすくなります。
まとめ
APIで最小ループを組むと、ループ設計は「プロンプトを改善する技術」というより、「失敗を前提にした制御構造」だと分かります。
生成結果が悪かったときに、どの条件が未達なのかを取り出し、次の試行へ戻し、それでも改善しなければ止める。この一連の流れを明示すると、AI出力の品質改善は感覚ではなく運用対象になります。
個人的には、ここまで小さく分解してようやく、Langfuseなどで何を観測すべきかも見えました。見るべきなのは最終回答だけではありません。attempt番号、未達ルーブリック、フィードバック、停止理由。次に観測へつなぐなら、この4つをまず残すのがよさそうです。

