When You Build a Minimal API Loop, You Stop Designing Prompts and Start Designing Stop Conditions
I implemented a minimal generate-evaluate-feedback-regenerate loop in a verification script. This post organizes the stop conditions and evaluation units that actually matter when stabilizing AI output.

In the previous article, I organized the idea of handling AI output not by trying to nail it with a single-shot prompt, but through a loop of generation, evaluation, feedback, and regeneration.
LLM Lab Prompts Alone Couldn't Stabilize Output, So I Started Running a Loop The idea of improving AI output through a generate-evaluate-feedback-regenerate loop, and the minimal steps to get started manually. https://llm-lab.dev/posts/llm-loop-engineering-first-step/
This time, as a step before moving that idea into an API implementation, I built the smallest possible verification script. It does not call an external LLM API; the generator is a mock. The goal is not to compare model performance, but to see what must be locked down as design targets the moment the loop becomes code.
Honestly, at first I thought it was as simple as “call the generation function, and if it fails, call it again.” But once it was in code, what mattered was not the retry itself, but the evaluation units, the granularity of feedback, and the stop conditions.
What I Wanted to Verify with the Minimal Loop
For this verification, I used short text generation—such as a customer inquiry reply draft—as the subject. What I implemented was a verification script prepared for this article. It returns mock generation results for an input task, evaluates the output against a rubric, and passes only the unmet items to the next attempt.
The four design elements I wanted to verify are as follows:
- Separate generation and evaluation into different functions
- Keep the rubric as judgment conditions in code
- Pass only unmet items as feedback to the next generation
- Always stop at the maximum number of attempts
Here I deliberately made the LLM API call portion a mock. Adding an API call would mix in model differences, authentication, latency, cost, and network failures. What I want to see first is whether the loop structure itself is observable.
Separating Generation and Evaluation
In the minimal setup, I separated generate() and evaluate(). In an actual API implementation, the former becomes a generation model call and the latter becomes an evaluation model call, or deterministic verification code.
function generate({ attempt, feedback }) {
// In production this becomes an LLM API call
}
function evaluate(output) {
const failed = rubric.filter((item) => !item.check(output));
return {
passed: failed.length === 0,
failed
};
}This separation is unremarkable but important. Judging the quality of generation results inside the generation context itself tends to make the evaluation lenient. Keeping them in separate functions lets you later swap out only the evaluation for LLM-as-judge, or shift some conditions to regex or schema validation.
The Rubric Becomes an Operational Unit, Not Just Text
The rubric for this experiment consists of the following three items:
const rubric = [
"State the conclusion in the first paragraph",
"List at least two next actions",
"Specify the owner's role"
];In the actual script, each item has a check and feedback. What matters here is treating the rubric not merely as evaluation text, but as an operational unit.
For example, “make the text easy to read” is understandable to human intuition. But when running a loop via API, you need to break it down to what satisfies a pass and what to return for each unmet condition.
Is this where we stop? Not because of the prompt, but because the evaluation vocabulary is too coarse.
This feeling only became strong once I actually translated it into code.
Success Case Log
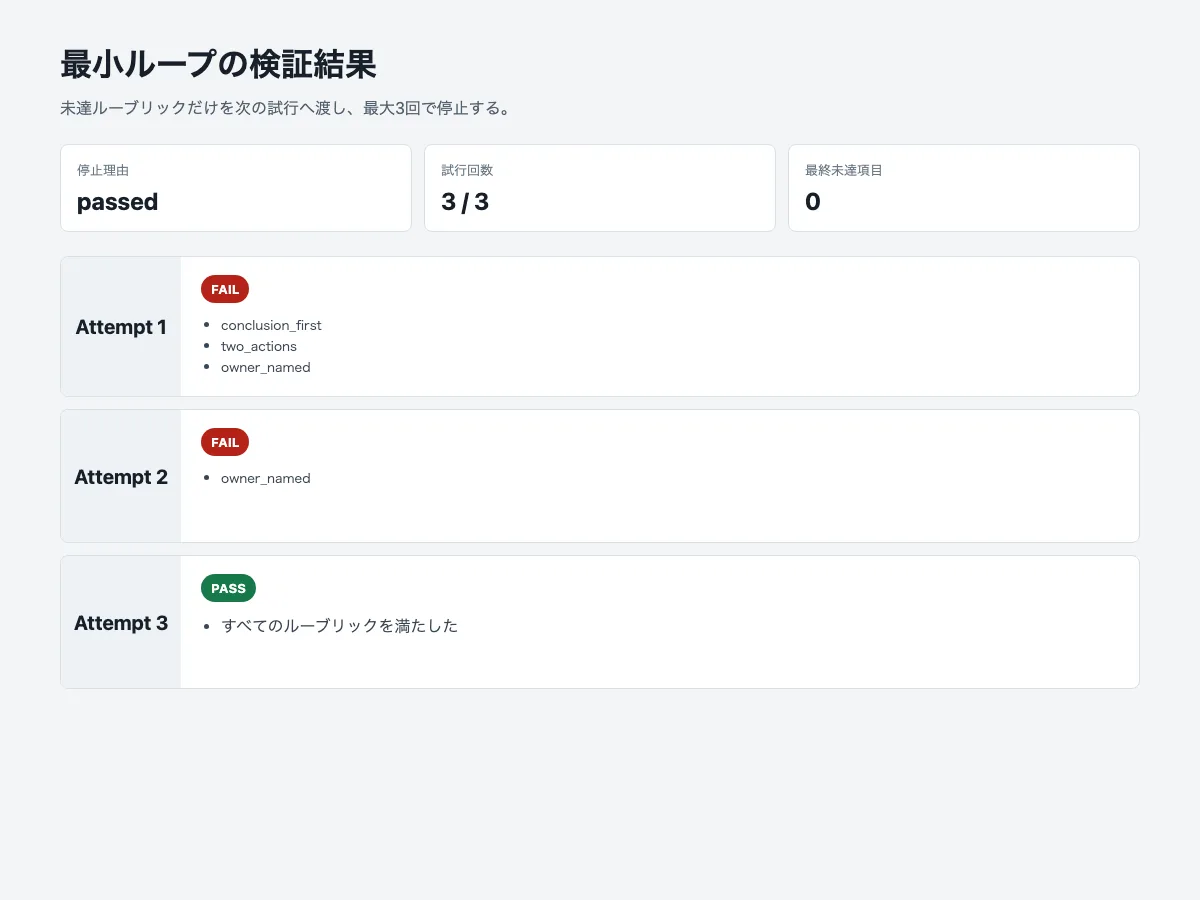
In the verification script, the success case passes on the third attempt.
{
"task": "Draft a customer inquiry reply",
"mode": "normal",
"maxAttempts": 3,
"stopReason": "passed",
"attempts": [
{
"attempt": 1,
"passed": false,
"failedRubricIds": [
"conclusion_first",
"two_actions",
"owner_named"
]
},
{
"attempt": 2,
"passed": false,
"failedRubricIds": [
"owner_named"
]
},
{
"attempt": 3,
"passed": true,
"failedRubricIds": []
}
]
}What I want to see in this log is not the final output text itself, but which evaluation items disappeared on which attempt. If you are going to operate a loop, “it feels like it got better” is not enough. You need to be able to track which condition was unmet and which feedback led to improvement.
Failure Cases Are Just as Important
The most dangerous thing when adding a loop is endlessly regenerating output that does not improve. Therefore, I deliberately added a mode to the verification script that does not improve.
npm run verify:stuckThis command uses a mock generator that keeps returning the same output. It stops after a maximum of 3 attempts, and the stopReason becomes max_attempts. This is a verification command prepared for the article, not a standard CLI. It exists to confirm that the loop always stops even when it cannot improve.
{
"mode": "stuck",
"maxAttempts": 3,
"stopReason": "max_attempts"
}If you do not design this, API cost, latency, and user experience all collapse. Especially when embedding this in a business system, “it was不合格 so we retried” is not enough. When the maximum attempt count is reached, you need to return the final output and unmet items to a human, or fall back to a different process.
What to Lock Down First in an API Implementation
Looking at this minimal implementation, what you should lock down first when building a loop with an API is not the model name or prompt text, but the following:
- How many attempts to allow
- What constitutes a pass condition
- Which unmet items to feed back into the next input
- What to return when it does not pass
- What to keep in logs and what to omit
Model selection and prompt improvements are of course important. But in loop design, relying solely on the model behaving smartly is unstable. You need to decide first how the system handles it when the model fails.
What It Looks Like When Swapping in an LLM API
This time generate() is a mock, but in practice you replace it with an LLM API call. For evaluation too, you can judge deterministically observable items in code, and route qualitative items like text quality to an evaluation model call.
const output = await generateWithModel({
task,
previousFeedback
});
const evaluation = await evaluateWithRubric({
task,
output,
rubric
});At this point, it is easier to handle generation and evaluation calls separately. On traces too, generation, evaluation, and regeneration appear as separate events, making it easier to trace where failures happened later.
Summary
When you wire a minimal loop with an API, loop design feels less like “a technique for improving prompts” and more like “a control structure that assumes failure.”
When generation results are poor, extract which conditions are unmet, feed them back into the next attempt, and stop if it still does not improve. Making this entire flow explicit turns AI output quality improvement from intuition into an operational target.
Personally, only by breaking it down this small did I finally see what should be observed in tools like Langfuse. What you should look at is not just the final answer. Attempt number, unmet rubric items, feedback, stop reason. If you are going to connect this to observability next, it seems best to start by preserving these four.

