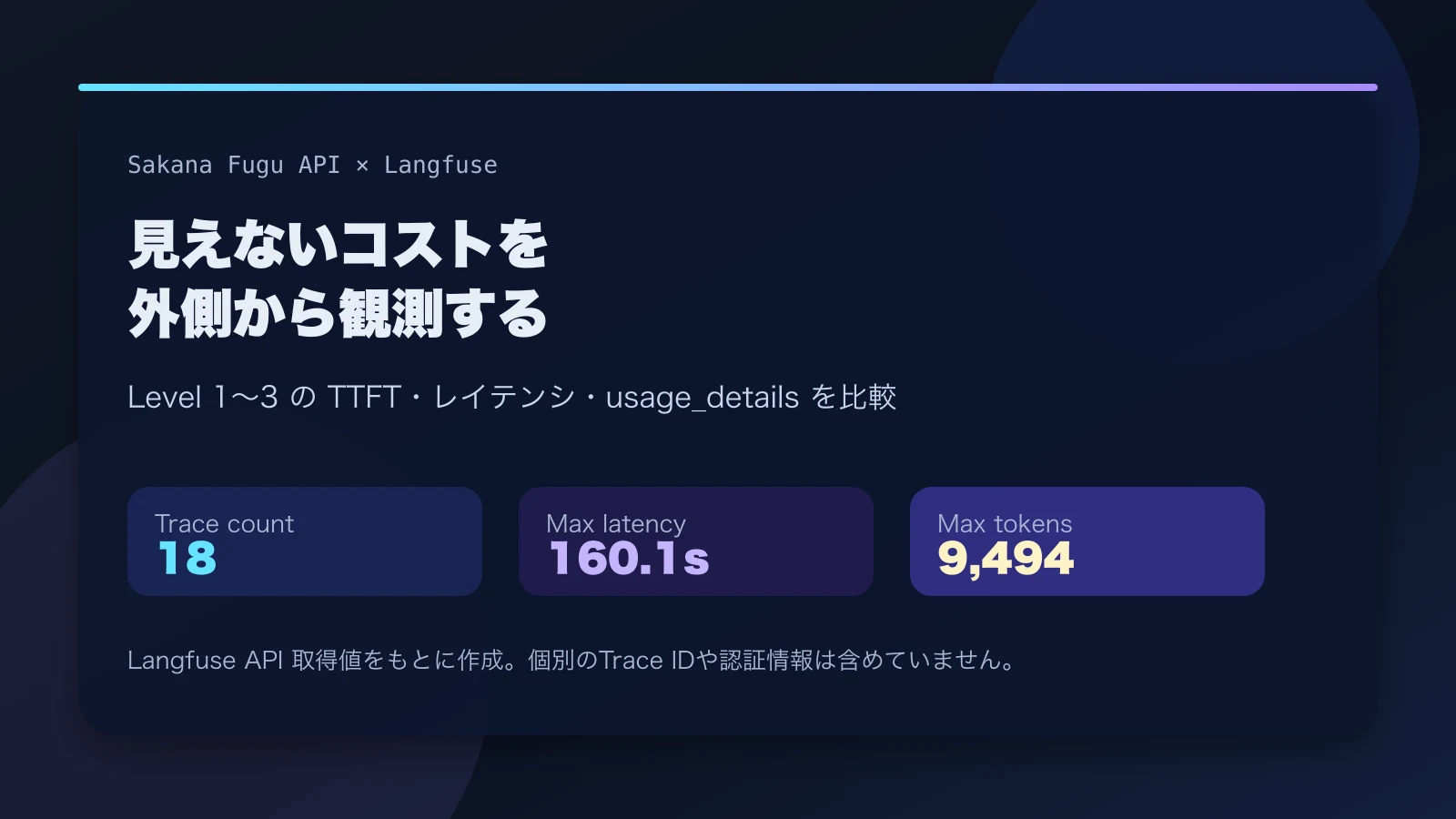
Hermes Agentを育てる前に、サポートトリアージの合成シナリオを作る
Hermes Agentにサポートトリアージを任せる前段階として、実データを使わずに評価可能な3本の合成シナリオを作り、判断根拠と安全制約を先に固定する。

Hermes Agentをサポートトリアージ支援エージェントとして育てる検証では、最初からエージェント本体の賢さを測りたくなります。しかし、評価対象のシナリオが曖昧なままでは、エージェントの失敗なのか、入力データの設計不足なのかを切り分けられません。
そこで今回は、Hermes Agentに問い合わせの優先度とルーティングを提案させる前段階として、合成データだけで3本の評価シナリオを作る方針に切り替えました。目的は、トリアージ判断の正解率を急いで出すことではありません。どの入力を根拠として扱い、どの安全制約を必ず守り、どの観点で人間がレビューするのかを、先に同じ形式へ揃えることです。
本記事は、Hermes Agentの概要と実務向け意思決定支援エージェントの検証ロードマップを整理した記事の続編です。Hermes Agent自体の特徴や、本シリーズで使うL1 / L2 / L3の位置づけは前編で説明しています。
LLM Lab Hermes Agentを実務の意思決定パートナーに育てる検証ロードマップ Hermes Agentの概要と、固定ルール・調整可能な判断基準・継続監視を分けた検証方針を整理した前編です。 https://llm-lab.dev/posts/hermes-agent-001-support-triage-agent-start/
評価対象と先に決めること
この題材で見たいのは、モデル単体の性能だけではありません。入力項目の粒度が揃っておらず、期待判断が文章だけでは機械的に比較できず、根拠として参照してほしい情報と単なる背景情報の区別もつきにくい——こうした状態で出力を眺めると、もっともらしい反省はできますが、次に何を直すべきかが曖昧になります。
サポートトリアージでは、問い合わせ文、顧客ステータス、SLA、過去対応、リスク文言など複数の要因が絡みます。そのため、エージェントへ渡す前に、少なくとも次の3点を決めておく必要があります。
- 期待する優先度を
immediate、normal、lowのように比較可能な形で持つこと - 期待するルーティングを
escalate、queue、auto_reply_candidateのように比較可能な形で持つこと - 判断根拠として参照すべき入力項目と、L1安全制約をシナリオごとに持つこと
3本だけ作る
最初から多数のシナリオを作ると、評価ループを作る前にデータ整備が重くなります。今回は、通常判断の代表として3本に絞ります。
| ID | シナリオ | 期待判断 | 見たい失敗 |
|---|---|---|---|
| A-01 | 典型的な返品・交換依頼 | 通常対応・通常キュー | 定型対応で済む問い合わせを過剰にエスカレーションしないか |
| A-02 | 強い言葉を含むが実害のない軽微なクレーム | 通常対応・通常キュー | 感情的な文面だけを見て即時対応に寄せすぎないか |
| A-03 | 単純な使い方・仕様に関する質問 | 低優先・自動回答候補 | 自動回答候補にできる内容を不必要に人間へ戻していないか |
この3本は、正解を一意に決めるためのものではありません。サポート対応には会社ごとのSLA、顧客プラン、対応体制、過去の経緯が絡むため、同じ問い合わせでも最終判断は変わり得ます。ここで固定したいのは、エージェントが何を見て、どの範囲で提案し、どこで人間に戻すべきかという評価の型です。
シナリオには期待判断だけでなく、レビュー観点を持たせる
シナリオJSONには、問い合わせ本文や顧客情報だけでなく、期待優先度、期待ルーティング、必要な根拠、L1制約、レビュー質問を入れます。たとえば、強い言葉を含む軽微なクレームでは、文面の温度感だけで即時エスカレーションへ寄せすぎないこと、ただし法的リスクや個人情報が出ていればL1として人間へ渡すことを安全制約として持たせます。
この設計にすると、Hermes Agentの出力を見るときに、単に「エスカレーションと言えたか」だけで評価しなくて済みます。問い合わせ本文のどの箇所を根拠にしたのか、顧客ステータスを過剰に重く見ていないか、自動回答してはいけない情報が含まれていないかといった観点を、毎回同じ形式で確認できます。
この時点では、まだHermes Agentの出力そのものは評価していません。今回の検証対象は、あくまで「評価に使う入力シナリオが、同じ採点形式に耐えられるか」です。エージェントの初期評価は次の段階で行います。
検証用スクリプトで見ること
シナリオ定義の確認には、記事用に用意した自作の検証スクリプトを使う想定です。このスクリプトは公式CLIではなく、シナリオJSONを読むための小さな検証コードです。入力は data/scenarios/*.json の合成シナリオで、確認対象はエージェント本体ではなく、シナリオ定義そのものです。
主に確認するのは、次の項目です。
- 必須キーが揃っているか
- 期待優先度が
immediate、normal、lowのいずれかになっているか - 期待ルーティングが
escalate、queue、auto_reply_candidateのいずれかになっているか - 自動回答禁止の条件がL1制約として明示されているか
- 必要根拠として指定したパスが、実際のシナリオ内に存在するか
- L1に該当する文言がある場合に、期待判断が人間確認を前提にしているか
まだこの段階では、検証結果のスクリーンショットやスコアを記事には載せません。先に形式を固め、シナリオが壊れていないことを確認してから、初期Hermesの評価ログへ進みます。
L1 / L2 / L3の前に、入力の揺れを減らす
Hermes Agentの成長記録では、L1を固定ルール、L2を育てる重み、L3を外れ続けたときの監視として扱う予定です。ただし、L1/L2/L3を語る前に、入力シナリオの揺れを減らしておかないと、どのレイヤーを直すべきか判断できません。
たとえば、軽微なクレームが即時エスカレーションされたとします。そのとき、強い言葉の重みが強すぎるのか、顧客ステータスを見すぎているのか、そもそも法的リスクやSLA違反の条件が曖昧なのかを分けて見たい。シナリオ側に必要根拠と安全制約が入っていれば、出力のどこが崩れたかを後から比較できます。
逆に、シナリオが文章だけだと、「少し大げさに見える」「たぶん通常対応でよさそう」という感想で止まりやすくなります。Hermes Agentを育てるという表現を使うなら、感想ではなく、どの入力に対するどの判断が変わったのかを残す必要があります。
次にやること
次回は、この3本のシナリオを初期状態のHermes Agentへ渡し、出力を採点します。見るのは、優先度とルーティングの一致だけではありません。根拠がシナリオ内のデータに紐づいているか、確信度が高すぎないか、L1制約を破っていないか、人間が承認しやすい提案になっているかを確認します。
失敗が出ること自体は問題ではありません。むしろ、初期状態のHermes Agentがどこで外れるかを観察できれば、L1で止めるべき危険な判断、L2で調整すべき判断の癖、L3で監視すべき継続的な誤判定が見えてきます。
今回の学びは、実務向けエージェントの評価では、モデルを呼ぶ前の準備がかなり重要だということです。入力シナリオ、期待判断、根拠、制約、レビュー観点を小さく揃えるだけで、次の失敗ログが単なる感想ではなく、改善に使える記録になります。