Hermes Agentを実務の意思決定パートナーに育てる検証ロードマップ
Hermes Agentを、ビジネスで使える支援エージェントとして育てる検証

Hermes Agentを、ビジネス判断を支援するエージェントとして育てる検証を始めます。
Hermes Agentとは
Hermes Agentは、Nous Researchが開発するオープンソースの自律型AIエージェントです。IDEに常駐するコーディング支援や、ひとつのAPIを会話画面で包んだチャットボットとは異なり、ツール、スキル、継続的な記憶、定期実行、サブエージェントを組み合わせ、ローカル環境やDocker、SSH先、クラウド上の実行環境で作業を続けることを想定しています。
公式ドキュメントが特に前面に出しているのは、経験を次の作業へ持ち越す学習ループです。Hermes Agentは、重要な事実や利用者の好みをセッションをまたぐ記憶として保持し、繰り返し使える手順をSkillとして読み込みます。必要なSkillだけを段階的に読み込むため、すべての手順を毎回プロンプトへ詰め込む構成ではありません。また、CLIだけでなくTelegram、Discord、Slackなど複数のメッセージング基盤から同じエージェントへ接続できます。
| 仕組み | 公式機能の概要 | 今回の検証で見ること |
|---|---|---|
| Memory | プロジェクトや利用者に関する重要な情報をセッション間で保持する | 過去の判断や修正を次の提案へどう反映するか |
| Skills | 必要なときに読み込む再利用可能な作業手順 | トリアージ基準を固定ルールと調整可能な判断基準に分けられるか |
| Tools・MCP | 外部情報の取得や操作能力を追加する | 問い合わせ情報を読む範囲と、副作用のある操作を分離できるか |
| Subagents | 分離した作業環境へ処理を委譲する | 将来、分類・根拠確認・監視を役割分担できるか |
| SOUL.md・Context Files | 応答姿勢やプロジェクト固有の前提を与える | 人間の承認を優先する姿勢と業務上の制約を維持できるか |
ただし、公式の「self-improving」という表現を、そのまま業務判断が自動的に正しくなるという意味では捉えません。記憶やSkillが更新されれば、誤った前提や一時的な例外も次回へ持ち越す可能性があります。公式機能にはMemoryやSkillへの書き込みを承認制にする設定もあるため、実務利用では「何を学習させるか」「誰が変更を承認するか」「変えてはいけないルールは何か」を先に設計する必要があります。
この問題意識から、本シリーズではHermes Agentの公式機能を紹介するだけでなく、固定ルール、調整する判断基準、継続的な誤判定の監視を分けて検証します。後述するL1 / L2 / L3はHermes Agent公式の用語ではなく、このPoCで判断ルールを管理するために採用した独自の整理です。
今回の題材は、カスタマーサポートの問い合わせトリアージとエスカレーション判断です。狙いは、対応そのものを完全自動化することではありません。受信した問い合わせの内容を見ながら、優先度と対応ルートを担当者が判断しやすい形で提案するエージェントを作ることです。
サポートトリアージはあくまで最初のユースケースです。ここで見たいのは、Hermes Agentを実務の意思決定に近づけるときに、どのルールを固定し、どの判断基準を育て、どこから人間に戻すべきかです。
なぜサポートトリアージをテーマにするのか
Hermes Agentをビジネスで使うための成長記録にするには、判断が曖昧すぎず、かつ単純な正解にもならないテーマが必要です。
カスタマーサポートの問い合わせトリアージは、この条件に合っています。
- 文面、緊急度、顧客の契約状況、過去のやり取りなど、判断材料が複数ある
- 即時対応、通常対応、低優先という優先度の出力が比較しやすい
- 即時エスカレーション、通常対応キュー、自動回答可というルーティングも比較しやすい
- 担当者の経験と勘に依存しやすい
- 外したときの理由を振り返りやすく、他の問い合わせ業務にも横展開しやすい
特に見たいのは、「初期状態のHermesが何を間違えるか」です。最初から賢いエージェントを演出するのではなく、何が足りないと判断が崩れるのかを記録します。
エージェントに任せる範囲
今回のPoCでHermesに任せるのは、トリアージの提案までです。
Hermesは、受信した問い合わせ(チケット)に対して次のような出力を作ります。
{
"priority": "immediate",
"routing": "escalate",
"rationale": [
"契約解除と返金を強く要求している",
"対応次第で法的手続きを示唆している",
"対象顧客は上位プランで影響範囲が大きい"
],
"confidence_score": 0.82,
"human_approval_required": true
}一方で、実際の返信内容や対応の確定は人間が行います。ここを自動化すると、誤判断の影響が直接顧客対応の品質や信頼に出るためです。
このシリーズでは、エージェントを「自動で返信する担当者」ではなく、「判断材料を整理して提案する補助者」として扱います。サポートトリアージでこの距離感を試し、うまくいく部分と危ない部分を他の問い合わせ業務にも転用できる形で残します。
L1 / L2 / L3で分ける
Hermesの判断は、3つのレイヤーに分けて考えます。
L1: 絶対に破らない固定ルール
L1は、フィードバックで変えてはいけない原則です。
- 法的リスク、契約解除、訴訟を示唆する文言は即時エスカレーションする
- 個人情報や機密情報が絡む内容は自動回答せず、必ず人間が確認する
- 自傷や危害を示す記述があれば最優先で人間へ渡す
- すでにSLA違反が発生しているものは最優先扱いにする
- 根拠なしに提案せず、人間の承認を迂回しない
ここは「育つ」対象ではありません。運用で成果が出ても、L1を弱めてしまうと危ない判断が通ってしまいます。
L2: 育てる重み
L2は、フィードバックを見ながら調整する重みです。
- 過去に誤検知が多かったキーワードやパターンの重みをどう調整するか
- 担当者ごとの得意分野や対応速度に基づくルーティングをどれくらい信じるか
- 顧客の契約プランやステータスを優先度へどれくらい反映するか
- 強い言葉そのものを、どれくらい緊急度として扱うか
Hermesが「育つ」と言えるのは、主にこのL2が改善していく部分です。
L3: 外れ続けたときの監視
L3は、個別提案の判断ではありません。
たとえば、同じカテゴリで誤判定が5件連続している場合、単に個別の判断を直すだけではなく、カテゴリ定義のずれや、運用ルールの変化など、Hermesが見ていない構造変化を疑う必要があります。
このときL3は、提案とは別に次のような警告を出す想定です。
{
"alert_type": "consecutive_misclassification",
"message": "このカテゴリのトリアージ判定が5件連続で採否と乖離しています。カテゴリ定義や運用ルールの変化を確認してください。"
}今回の初期PoCでは、まずL1/L2で通常判断を評価します。L3は後続回で扱います。
最初に作る検証シナリオ
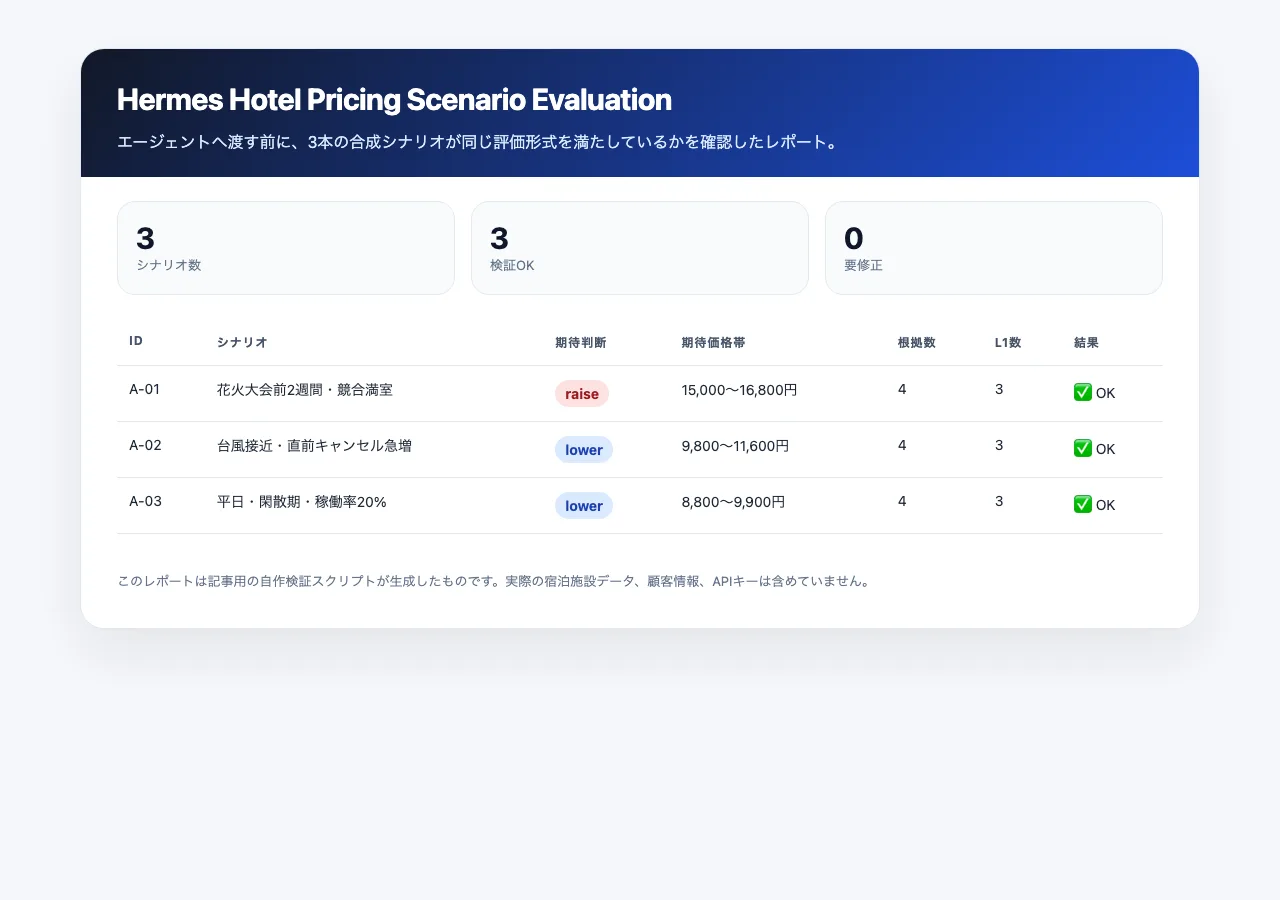
最初から全シナリオを作ると、評価ループよりデータ作りが重くなります。まずは通常判断を試すための3シナリオだけに絞ります。
| ID | シナリオ | 期待判断 |
|---|---|---|
| A-01 | 典型的な返品・交換依頼 | 通常対応・通常キュー |
| A-02 | 強い言葉を含むが実害のない軽微なクレーム | 通常対応・通常キュー |
| A-03 | 単純な使い方・仕様に関する質問 | 低優先・自動回答可 |
この3本で見たいのは、Hermesが「それっぽい文章」を出せるかではありません。
- 優先度とルーティングの判断が合っているか
- 根拠がチケット内容に紐づいているか
- 確信度が高すぎたり低すぎたりしないか
- L1を破る提案をしていないか
まずはここを採点し、初期状態の弱さを記録します。
なお、シナリオはすべて架空の問い合わせ文と架空の顧客情報で合成します。特定の業界や企業を想起させる固有名詞は使わず、抽象化した問い合わせカテゴリと対応チームだけで進めます。
今回作ったもの
検証用の実データや作業ファイルは、公開リポジトリではなく手元の非公開ワークスペースに置いています。
サポート業務の検証では、問い合わせ文や顧客対応に近い形の情報を扱う可能性があります。たとえ今回は合成データから始めるとしても、後から実データや固有の業務メモが混ざる余地があります。そのため、GitHubで公開する記事側には「どういう構造で検証しているか」だけを残し、具体的なデータや内部メモは公開しない方針にします。
主な中身は以下です。
- PoC README
- 最小設計メモ
- SQLite想定のschema.sql(チケット、トリアージ判断、フィードバック、エスカレーション)
- HermesのSOUL.md
- L1/L2のコンテキスト
- 最初に試す3シナリオのJSON
- 手動採点用メモ
この時点では、まだ自動評価スクリプトは作っていません。次にやるのは、3本のシナリオを初期Hermesに投げて、どの判断が外れるかを記録することです。
次に確認すること
次回は、上の3シナリオを実際にHermesへ渡します。トリアージの正解率だけを見るのではなく、ビジネス判断支援エージェントとして何が足りないのかを観察します。
そこで、以下を記録します。
- 期待通りに優先度とルーティングを判断できるか
- 根拠が入力JSONのデータに対応しているか
- 軽微なクレームを過剰にエスカレーションしていないか
- 強い言葉だけを理由に危険な判断へ寄っていないか
最初の評価では、失敗が出る方が素材としては重要です。どこで判断が崩れたかが見えれば、次にL1やL2をどう直すべきかが分かります。
続編
次の記事では、Hermes Agentへ入力する前に、サポートトリアージの合成シナリオ、期待判断、根拠、安全制約を同じ形式へ揃えています。
LLM Lab Hermes Agentを育てる前に、サポートトリアージの合成シナリオを作る 実データを使わず、評価可能な3本の合成シナリオと安全制約を設計した続編です。 https://llm-lab.dev/posts/hermes-agent-002-support-triage-scenarios/