Sakana Fugu APIをLangfuseで観測し、マルチエージェントの見えないコストを考える
Sakana FuguのOpenAI互換APIをLangfuseで計装し、Level 1〜3のタスクでレイテンシ、消費トークン、TTFTがどう変化するかを観測した実践レポート。
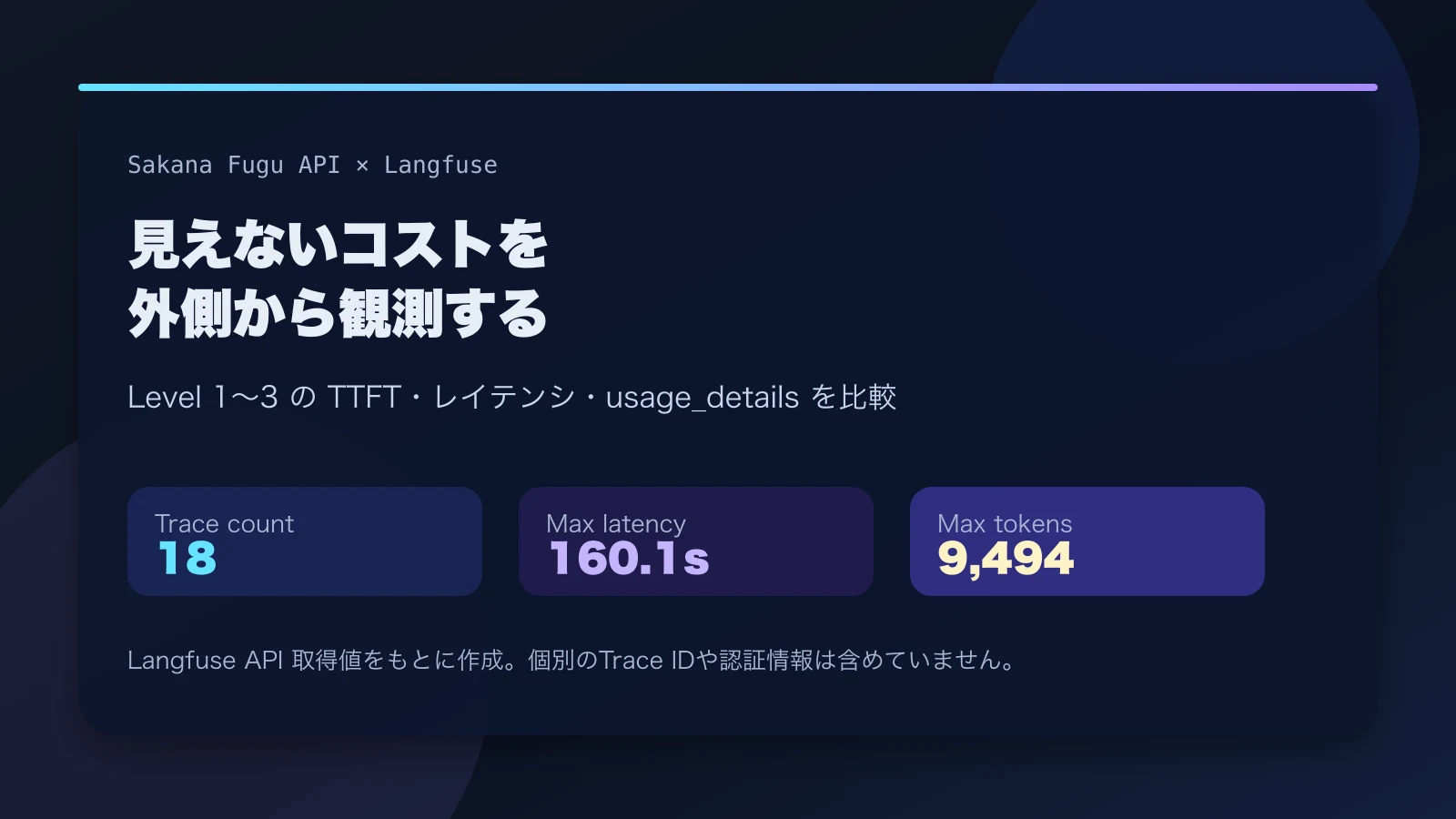
Sakana Fuguをサブスク契約し、複数モデルや複数役割を束ねた統合型APIを運用上どこまで信頼できるかを、外側から観測する計画を立てました。
Sakana Fuguを契約したので、マルチエージェントAPIの見えなさをLangfuseで観測する OpenAI互換APIとしての性質と、ブラックボックスな協調推論を外側から観測するための検証計画。 https://llm-lab.dev/posts/sakana-fugu-langfuse-observability-plan/
今回はその続きで、実際にFugu APIをLangfuseで計装し、難易度の違う3レベルのプロンプトを投げて、総レイテンシ、TTFT、消費トークン、usageDetailsがどう動くかを測っています。
測り方はシンプルで、FuguをOpenAI互換APIとして呼び、LangfuseのOpenAI互換クライアントで計装し、Level 1から3までのプロンプトを送りました。そのうえで、Langfuse APIからTraceとObservationを取り直し、入力、出力、レイテンシ、usage、ObservationをAPI境界の観測値として確認しています。
FuguがLLMの内側で何をしているかは契約者からは見えませんが、外側から追える値はLangfuse越しに残せます。
まずLangfuseへつなぐ
FuguはOpenAI互換APIとして呼べるので、LangfuseのOpenAI互換クライアントにそのまま載せられました。既存のOpenAI SDKやLangfuse計装をほぼ書き換えずに使えるため、手元のコードではモデル名をfuguに、ベースURLをSakanaのエンドポイントに向けるだけで、レイテンシもusageもTraceとして残り始めました。
計装の起点はこれだけです。metadataに実験名を入れておくと、あとからこの実験単位でTraceをまとめて回収できます。
import os
from langfuse.openai import OpenAI
client = OpenAI(
base_url="https://api.sakana.ai/v1",
api_key=os.environ["SAKANA_API_KEY"],
)
response = client.chat.completions.create(
model="fugu",
messages=[{"role": "user", "content": "おはよう"}],
name="fugu-smoke-test",
metadata={"experiment": "fugu-langfuse-observability"},
)最初は「おはよう」の一言だけ投げて、TraceとusageとTTFTがLangfuseまで届く計測経路ができているかを確認しました。短時間で終わる処理だと、送信キューがフラッシュされる前にプロセスが終わってTraceが欠けることがあるので、この種の検証では明示的にflush()を呼んでキューを吐き出してから終了させています。
投げたプロンプト
プロンプトはLevel 1とLevel 2を各3問、Level 3を2問用意しました。呼び出しは2系統に分け、非ストリーミング呼び出しではusageと総レイテンシを、ストリーミング呼び出しではTTFTを見ています。
| Level | 件数 | 入力の概要 | 取得した主な指標 |
|---|---|---|---|
| Level 1 | 3問 | 新幹線の所要時間、日本の首都、PythonのHello World | ベースラインのレイテンシ、usage、TTFT |
| Level 2 | 3問 | ラベルが間違った果物箱の推論、給与計算、帽子色パズル | 推論タスクでのレイテンシとトークン増加 |
| Level 3 | 2問 | 孫子の兵法を使ったAgentOpsランブック、プロンプトインジェクション対応ランブック | 複数視点の統合生成での長時間化と大きなusage |
各Levelの送信には、記事用に用意した自作の検証スクリプトを使いました。標準のCLIではなく、LevelごとのプロンプトをFugu APIへ送り、Langfuseにその実験名でTraceを残すだけの小さなスクリプトです。 手元では次のような呼び分けで動かしました。
# 非ストリーミング(usageと総レイテンシ用)
python scripts/01_level1_simple.py
python scripts/02_level2_reasoning.py
python scripts/03_level3_complex.pyFuguにLangfuseのTraceを読ませる
今回Fugu APIの実験結果を、Fugu自身に整理させてみました!
Langfuse for Agents のドキュメントを渡し、実験名でTraceとObservationを取得する方針を作らせました。そこから、Levelごとのレイテンシ、TTFT、usageを集計し、記事用のグラフまで出してもらっています。単に「Fuguに質問した」だけではなく、Fuguを観測データの読み取り役として使った形です。
観測対象のモデルに観測結果の整理までやらせるのは、AgentOpsっぽさがあって面白い。
実際の取得では、Trace詳細を1件ずつ引くとレート制限に当たったため、Observation一覧APIへ切り替えました。ストリーミング呼び出しではLangfuse上のusageが0として記録されていたので、usageは非ストリーミングのObservation、TTFTはストリーミングのObservationから読むように分けています。

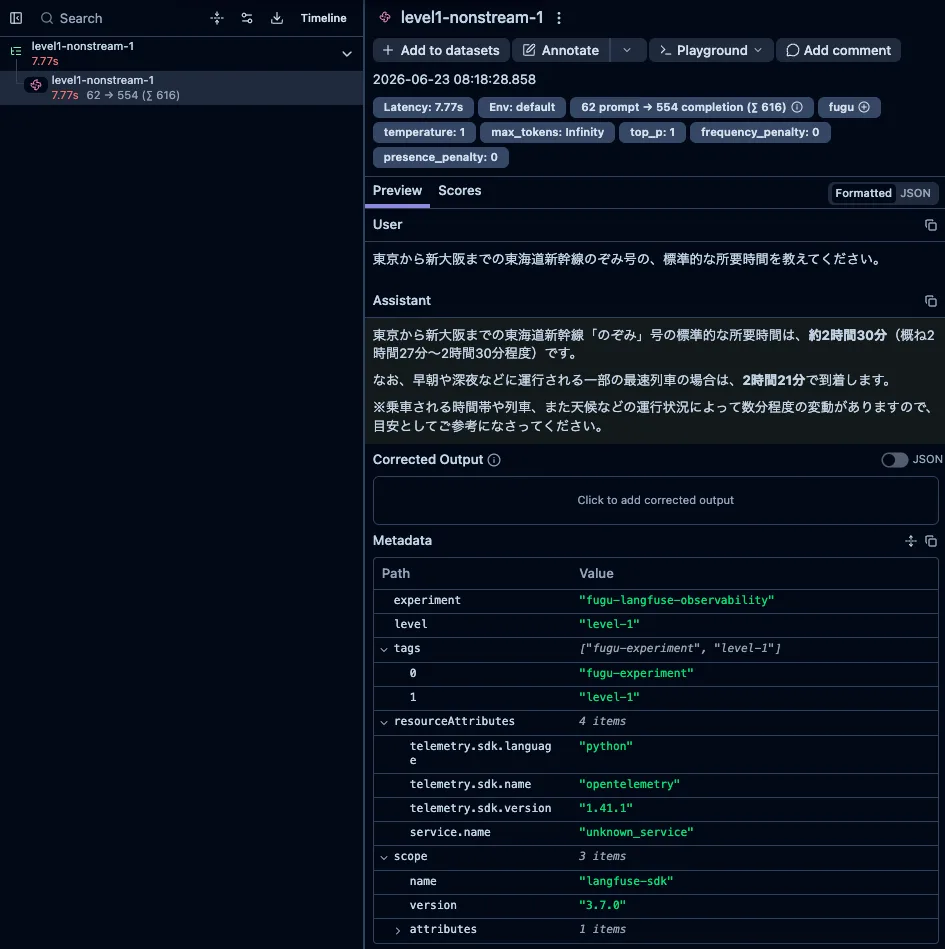
Level 1 単純な事実確認
Level 1は、新幹線の所要時間、日本の首都、PythonのHello Worldという、答えが一意に決まる3問です。代表として新幹線の質問を載せます。
東京から新大阪までの東海道新幹線のぞみ号の、標準的な所要時間を教えてください。
このレベルの非ストリーミング総レイテンシは約4.8〜7.8秒、ストリーミング時にLangfuseで記録されたTTFTは約5.5〜7.9秒でした。合計トークン数は約358〜616トークンです。
短い事実確認でも、合計で数百トークンが計上されている点は覚えておきたいところです。画面に出てくる回答が数行でも、usage上はそれなりの厚みがあります。出力された文字数の見た目だけでコスト感を読むとずれます。
Level 2 論理的推論
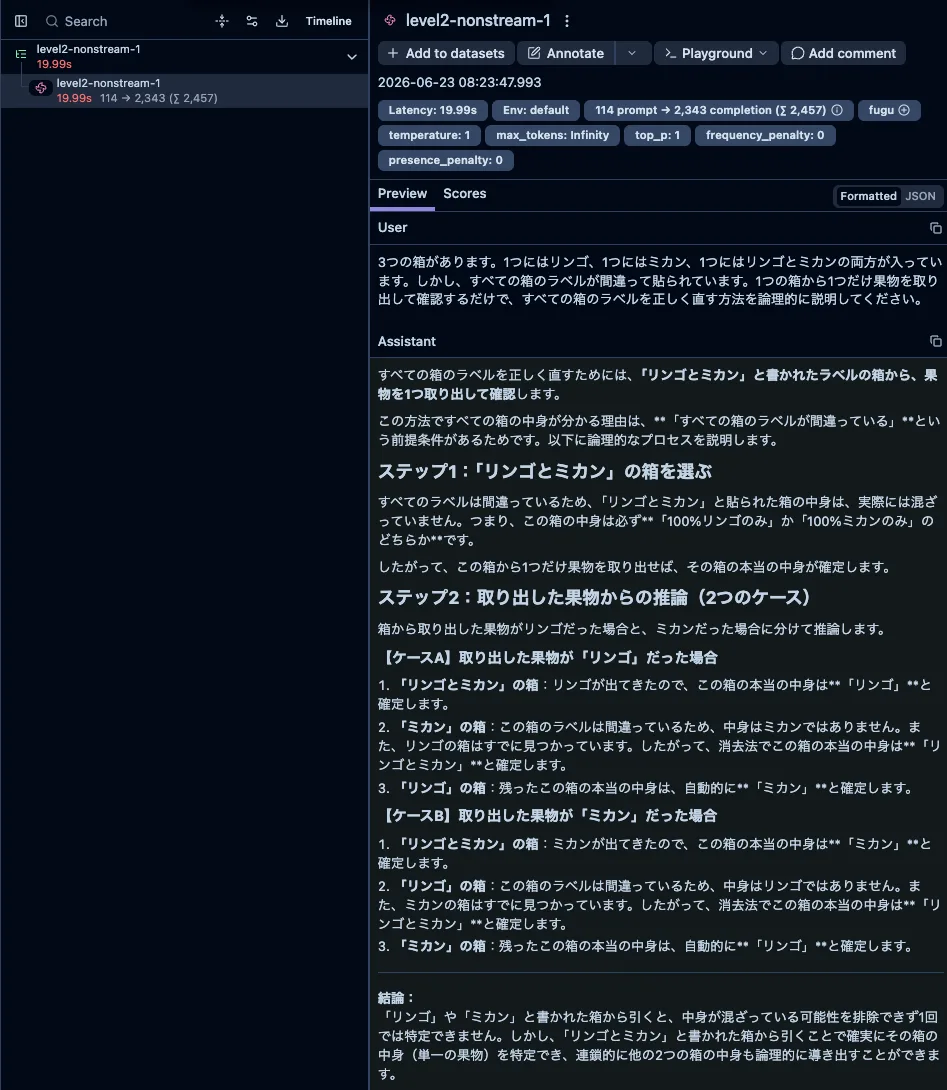
Level 2は、ラベルが全部間違っている果物箱から最小の確認で中身を当てる問題、条件付きの給与計算、帽子の色当てパズルという、少し考える3問です。
非ストリーミング総レイテンシは約6.2〜20.7秒、ストリーミング時のTTFTは約7.3〜14.9秒、合計トークン数は約526〜2,457トークンと、Level 1より幅が広がりました。
面白いのは、同じLevel 2でも給与計算は約6.2秒、526トークンに収まり、果物箱や帽子色パズルよりかなり軽かったことです。難易度を3段階に分けたつもりでも、実際の重さを決めているのはLevel番号そのものではなく、どれだけ探索や場合分けを求める問題か、推論過程をどこまで言語化させるか、という質の差に見えます。同じレベルのラベルを貼っても、中身次第でレイテンシもトークンも倍以上変わります。
Level 3 複数視点の統合ドキュメント生成
Level 3は、長めの統合タスクを2本投げました。1本目は孫子の兵法をLLMOpsとAgentOpsのインシデント対応フローへ落とし込むランブック、2本目はセキュリティ、プロダクト、SREの3視点からプロンプトインジェクション対応ランブックを作るものです。どちらも、複数の観点を一つの文書にまとめさせる狙いがあります。
ここで待ち時間の桁が変わりました。非ストリーミング総レイテンシは約115.0〜144.3秒、合計トークン数は約7,617〜9,494トークンです。Level 1やLevel 2が秒の世界だったのに対し、Level 3は2分前後を平気で使います。叩いてしばらく無反応なので、最初は止まったのかと思いました。
TTFTは計測する層で値が割れました。手元のストリーミング計測では、Level 3の1本目で最初の本文チャンクが届くまで約72.6秒かかっていました。一方、Langfuse APIのtimeToFirstTokenでは、Level 3の2本が約13.7〜15.5秒です。同じ「TTFT」というラベルでも、桁が一つ違います。
ここ、かなり大事です。TTFTという同じ名前でも、SDK、ストリームのチャンク、本文文字列の取り方で意味がズレます。
SDKがどのイベントを最初のトークンと見なすか、ストリームのどのチャンクを起点に取るか、本文文字列が実際に乗ってきたタイミングで測るか。この取り方の違いで、同じ呼び出しでも数十秒の差が出ます。TTFTを運用指標として使うなら、どの層で測った値かをそろえないと比較になりません。
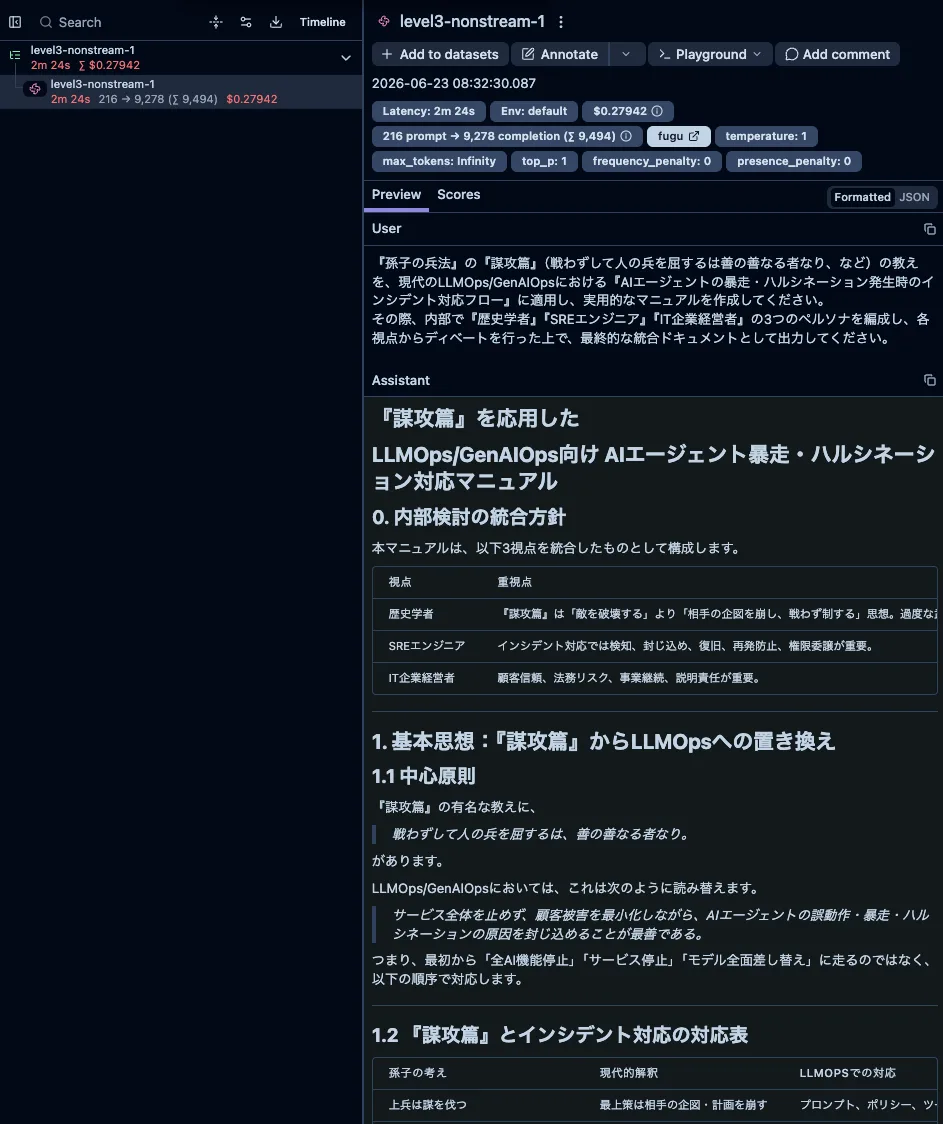
usageDetailsから分かったことと分からなかったこと
合計トークン数はLevel 3で大きく膨らみました。最終出力の長さだけを見ると、ここまでのトークン数になる理由は完全には説明しきれません。複数視点を内部でどう束ねているにせよ、API境界のusageには見た目以上の厚みが乗っています。
ただ、Langfuse APIのusageDetailsを確認しても、orchestration_tokensのような内部協調専用のフィールドは出てきませんでした。見えるのは入力、出力、合計、キャッシュ済み入力、推論トークンといった一般的な内訳だけです。
{
"input": 216,
"output": 9278,
"total": 9494,
"input_cached_tokens": 0,
"output_reasoning_tokens": 0
}最初はここで「orchestration tokenは見えないのか」と思いました。その後にFuguのドキュメントを読み直すと、見る場所が違っていそうだと分かりました。
Fuguのドキュメントでは、生成リクエストにはChat Completions APIよりResponses APIの利用が推奨されています。さらにFugu Ultraでは、user-visibleなmodel workとorchestration workを分けるusage fieldsがあり、input_tokens_details.orchestration_input_tokensやoutput_tokens_details.orchestration_output_tokensとして返ると説明されています。
つまり、今回LangfuseのusageDetailsで見えなかった理由は、内部協調が存在しないからではなく、見ていたAPIとフィールドが違った可能性があります。今回の計装はChat Completions寄りで、Langfuse側でもOpenAI互換のusageとして正規化された値を見ていました。Fugu UltraのResponses APIが返すraw usageまで保存して突き合わせないと、orchestration workの内訳までは判断できません。
Langfuse側は、実際にAPIから引き直せました。実験名でTraceを絞り込み、Observation APIからusageDetails、timeToFirstToken、latency、modelを取得すると、ストリーミング呼び出しではusageが0になり、非ストリーミング呼び出しではinput/output/totalが入っていることを確認できます。これは記事中のLevel別の数値とも一致します。
一方で、Fugu Responses APIのraw usage確認は、まだ詰まりがあります。短い入力で/v1/responsesへfugu-ultraを投げるところまでは試しましたが、手元の呼び出しではHTTP 200で{}が返り、usage fieldを取得できませんでした。認証や到達性の問題ではなさそうですが、リクエスト形式、モデル指定、SDK経由との差分をもう少し確認する必要があります。
次に確認したいのは、同じLevel 3のプロンプトをResponses APIで投げ、raw responseのusage fieldsとLangfuseのObservationを並べることです。Langfuse for AgentsのCLIやAPIを使えば、実験名でTrace/Observationを引き直せることは確認できました。そこにFuguのraw responseをJSONLで残しておけば、少なくとも次の対応関係は見られるはずです。
| 見たいもの | 見る場所 |
|---|---|
| 最終的なinput/output/total tokens | Fugu Responses APIのraw usage |
| orchestration input/output tokens | Fugu Ultraのinput_tokens_details / output_tokens_details |
| Langfuse上の正規化後usage | Langfuse ObservationのusageDetails |
| TTFTと総レイテンシ | Langfuse Observationと手元のストリーミング計測 |
ここまで見ると、「Langfuseでは見えなかった」のではなく、「Langfuseに入る前のraw usageと、Langfuseに入った後のusageを分けて見ていなかった」と言えそうです。この差分は、Fuguを本当に運用で使うならかなり大事です。Responses APIのraw usage取得は次の宿題として残りました。
内部役割ごとの会話ログが見えているわけではありません。観測できたのは、API境界でのusageとレイテンシとして、Level 3が明確に重いという事実です。内部対話が覗けた、という話ではありません。
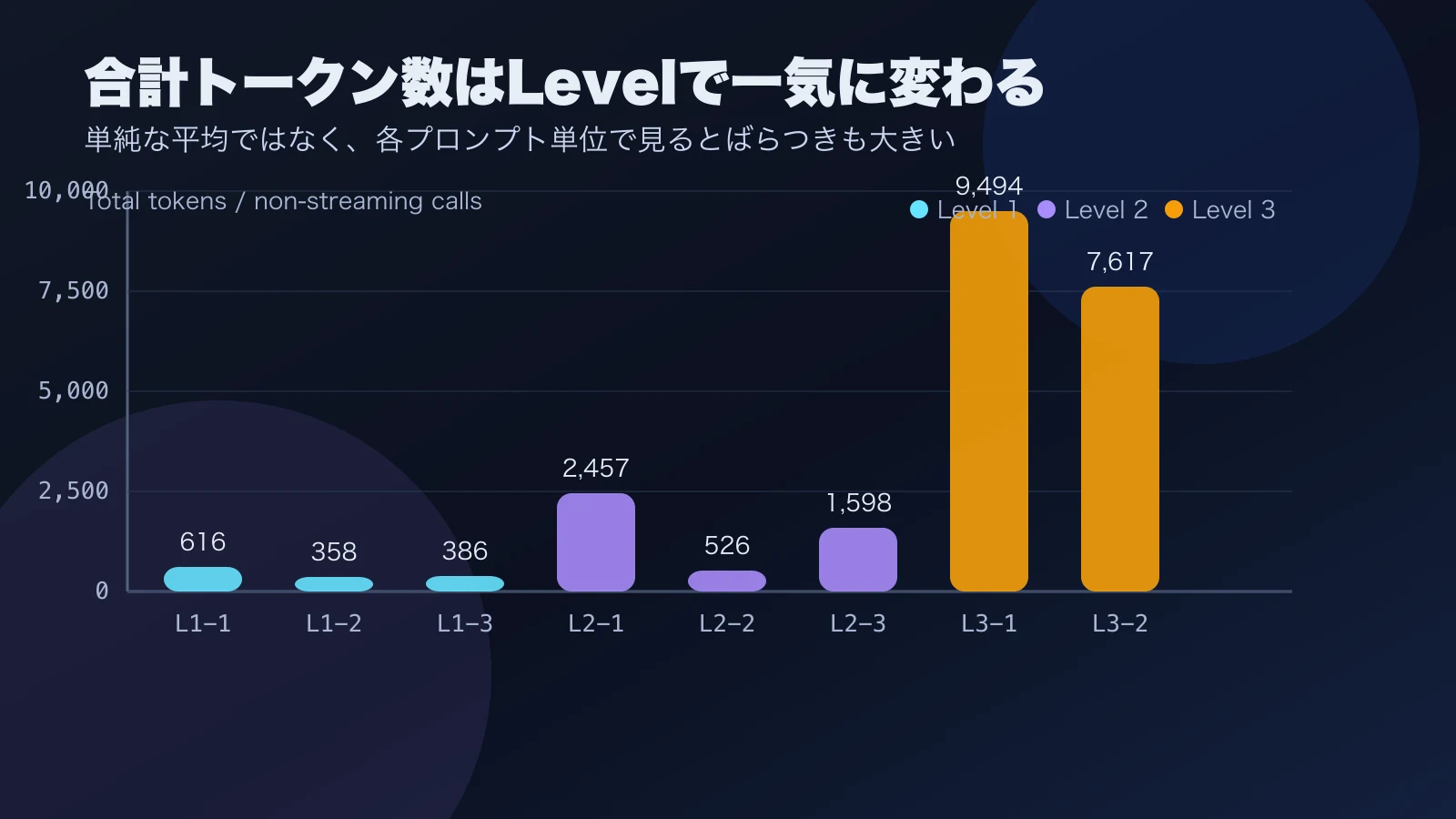
このグラフからは、Level 3の合計トークン数が突出している一方で、Level 1でも短い回答に数百トークンが計上され、Level 2の中でもばらつきが大きいことが読めます。「長い出力だからトークンが多い」「内部で複数役割が動くからトークンが多い」のどちらか一方だけで全部を説明するのは無理がありそうです。運用観点では、プロンプトの種類ごとにusageのベースラインを作っておき、そこから跳ねたTraceを個別に追いかける方が現実的だと感じました。
Fuguは自作エージェントの代わりになるか
今回の数値を踏まえると、Fuguは「少し賢いLLMへの置き換え」というより、「重い推論や複数視点の整理をまとめて任せるAPI」として見たほうが、使いどころを考えやすいです。
LangChainやFlueで思考、実行、検証のループを自作すると、状態管理、エラーハンドリング、プロンプト調整を自分で抱えることになります。Fuguはその一部をAPIの向こう側へ寄せられる選択肢に見えました。単純な事実確認や定型処理なら、通常のLLM呼び出しや手元のエージェントで足りる場面が多そうです。一方で、複雑な論理構築や複数ペルソナの統合が必要な場面では、Level 3のような重い処理をまるごとFuguに渡す余地が出てきます。
ただし内部構造は契約者から完全には見えません。だからこそ、TTFT、総レイテンシ、usage、エラー率を外側から継続的に追う前提が要ります。どこまでをAPIに任せ、どこからを自分たちのエージェントフレームワークで制御するか。この線引きは、性能の印象ではなく、Langfuseに残る観測値で判断していくのが筋だと考えています。
まとめ
今回観測できたことを並べておきます。
- Level 1とLevel 2は各3問、Level 3は2問を投げた。
- ストリーミング呼び出しではTTFT、非ストリーミング呼び出しではusageを見た。
usageDetailsには、内部協調専用のフィールドは出ていなかった。- Level 3では総レイテンシと合計トークン数が大きく増えた。
- TTFTは計測する層によって値がズレた。
- Fugu UltraのResponses API raw usageには、orchestration workの内訳が出る可能性があるが、手元の短い確認では
/v1/responsesがHTTP 200で{}を返し、まだusage fieldまでは取れていない。
運用イメージとしては、Fugu APIを常時すべてに使うというより、重いタスクのときだけ呼び出す外部の専門チームのように扱うほうが、コストと制御性のバランスを取りやすそうです。これは現時点の手応えで、もっとプロンプトの種類を増やして観測しないと言い切れない部分も残っています。次は、Responses APIのraw usageとLangfuse Observationを突き合わせ、何がトークンを押し上げているのかをもう少し詰めてみるつもりです。

