Sakana Fuguを契約したので、マルチエージェントAPIの見えなさをLangfuseで観測する
Sakana Fuguをサブスク契約して分かったOpenAI互換APIとしての性質と、ブラックボックスな協調推論を外側から観測するための検証計画。
Sakana AIの新しいモデルとして話題になっているSakana Fuguを、まずはサブスク契約してみました。 本記事の目的は、Sakana Fuguそのものの性能をこの時点で評価することではありません。見たいのは、複数モデルや複数役割を束ねる統合型APIを、運用上どこまで信頼して任せられるかです。
そのために、Fuguの回答内容だけでなく、TTFT、総レイテンシ、トークン量、再実行時の揺れをLangfuseで観測し、ブラックボックスな協調推論の外形をつかむ準備をします。
マルチエージェントを指揮する、一つのモデル Sakana Fugu https://sakana.ai/fugu/
気になるのはブラックボックス性
Fuguの魅力は、単一モデルにプロンプトを投げるだけではなく、複数のモデルや役割を使い分けながら複雑なタスクを解くという点にあります。公開情報では、タスクに応じた役割分担や協調的な推論が重要なコンセプトとして語られています。
この方向性はかなり面白いです。一方で、内部の判断がどこまで見えるのかには、正直かなり興味があります。
自分でAgentを組む場合、Thinker、Worker、Verifierのような責務分割を設計し、各ステップの入力、出力、失敗時の戻し方を自分で管理します。一方で、Fuguのような統合APIでは、その複雑さをAPIの向こう側に寄せられる可能性があります。
ただ、LLMOpsとして見ると、便利さと同時に別の問いが出てきます。
- 単純な質問でも常に重い協調処理が走るのか
- 複雑なタスクのときだけレイテンシやトークン消費が跳ねるのか
- 失敗時に、内部で再試行や検証ループが走った痕跡は外側から見えるのか
- 自作Agentと比べて、どこまでを任せ、どこからを自分で制御すべきなのか
内部ステップそのものがAPIレスポンスに出ないなら、外側から観測できる情報で推定するしかありません。 ここでLangfuseを使います。見えるのは内部実装そのものではありませんが、レイテンシ、usage、失敗率、再実行時の揺れから、運用判断に必要な手がかりは得られるはずです。
Langfuseで見る指標を先に決める
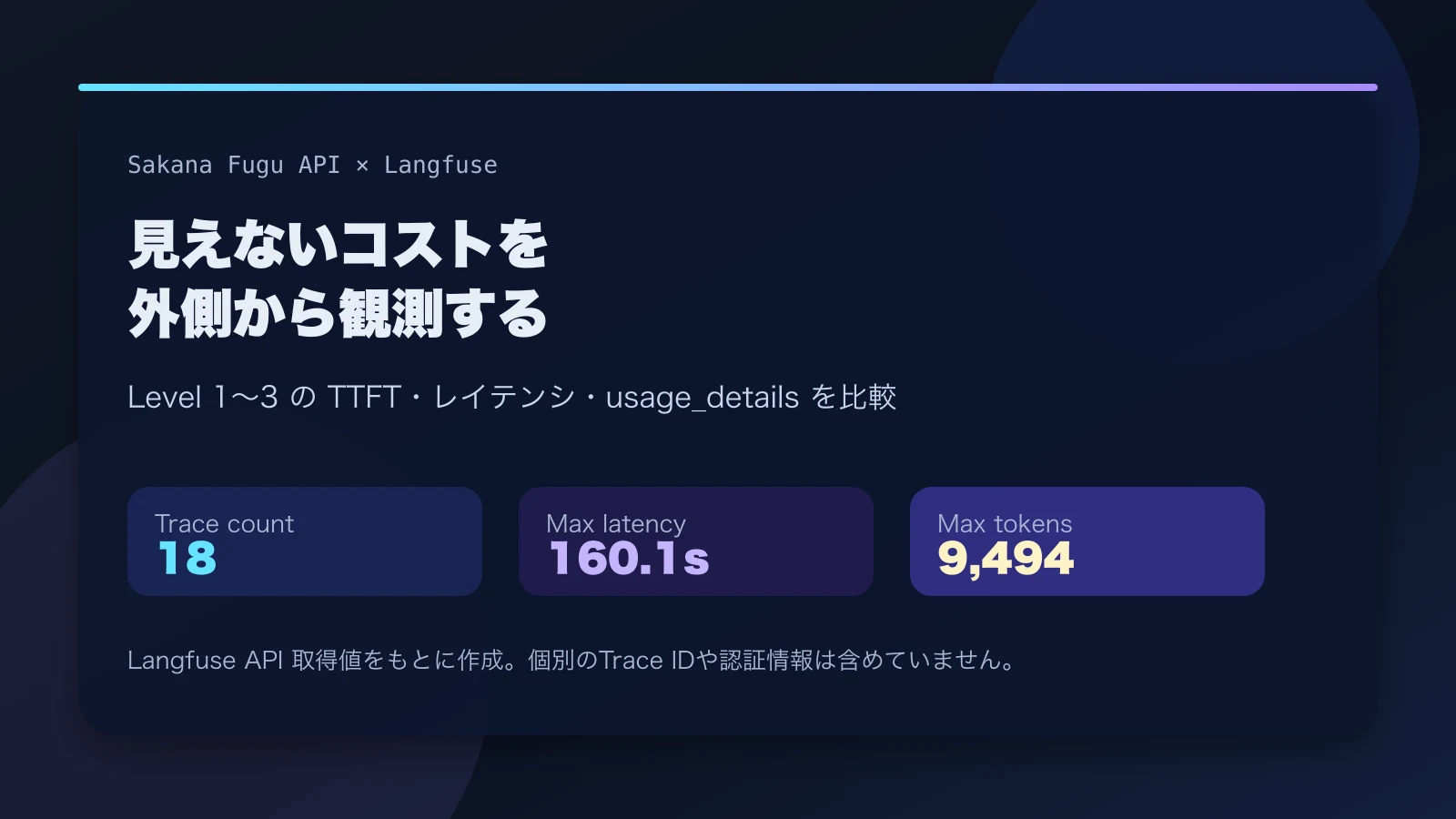
今回の検証では、Fugu APIへのリクエストをLangfuseに流し、少なくとも次の指標を同じ形式で残す予定です。
| 観測したいもの | 見る理由 |
|---|---|
| TTFT | 最初のトークンまでの時間から、内部準備やルーティングの重さを推定する |
| 総レイテンシ | 単純タスクと複雑タスクで処理時間がどう変わるかを見る |
| 入出力トークン数 | 協調的な処理が外側のusageにどう反映されるかを見る |
| 成功率 | 構造化出力や制約付きタスクで破綻しないかを見る |
| 再実行時のばらつき | 同じ入力でルーティングや品質が揺れるかを見る |
統合APIは内部で複数の判断をしている可能性があるため、単発の体感だけでは評価がぶれます。入力の種類を分け、同じ観測項目で比較する必要があります。
3段階で試す
まずは、タスクを3段階に分けて投げます。
Level 1は単純な事実確認です。短い質問、明確な答え、外部ツールを必要としない入力を投げ、最短経路で返ってくるときのベースラインを取ります。ここでは高い推論能力よりも、余計な重さが乗らないかを見ます。
Level 2は論理的な推論です。複数条件を整理する問題、仕様の矛盾を見つける問題、短い設計判断を伴う問題を投げます。ここではTTFTと総レイテンシの伸び方を見ます。もし内部で検討や検証のステップが増えるなら、単純質問とは違う時間の使い方になるはずです。
Level 3は自律的な協調が必要になりそうなタスクです。たとえば、要件整理、実装方針、テスト観点、リスク洗い出しを同時に求めるような入力を投げます。ここでは出力品質だけでなく、トークン数、レイテンシ、再実行時のばらつきが非線形に増えるかを見ます。
ここで見たいのは、Fuguの内部実装を暴くことではありません。外側の利用者として、どの種類の仕事を任せると費用対効果が合うのか、どの仕事は自作Agentとして分解した方がよいのかを判断することです。
自作Agentと統合APIの比較軸
個人的に一番知りたいのは、Fuguのような統合APIが、自作Agentのどこを置き換えるのかです。
自作Agentには、観測しやすいという強みがあります。各ステップのプロンプト、ツール呼び出し、評価、再試行を自分で記録できます。その代わり、実装と運用の責任も自分で持つ必要があります。プロンプトの劣化、モデル変更への追従、失敗時のリカバリ、コスト上限の管理が全部こちらに来ます。
統合APIは、この負担をかなり隠蔽してくれる可能性があります。一方で、隠蔽された部分は観測しづらくなります。つまり比較すべきなのは、単純な精度ではなく、コスト、レイテンシ、制御性、観測可能性、開発者体験のバランスです。
このあたりを、Langfuseのtraceを見ながら検証していきます。
まずは観測できる形にしてから遊ぶ
新しいモデルが出ると、すぐに面白いプロンプトを投げたくなります。もちろん、それはそれで楽しいです。
ただ、今回はあえて先に観測設計から入ります。Fuguの価値が「複数モデルや複数役割をいい感じに束ねること」にあるなら、出力だけではなく、外側から見える挙動の変化も含めて見た方がよいからです。
まずはOpenAI互換APIとして接続し、Langfuseへtraceを残し、Level 1からLevel 3までの入力セットを作る。そこまで準備してから、実際の回答品質、速度、コスト感、再実行時の揺れを見ます。
サブスク契約した直後の勢いで書いていますが、ここからが本番です。次は実際にFugu APIを叩き、Langfuse上でどのような差が見えるかを検証します。