Flue 1.0 BetaでGitHub Issueトリアージエージェントを動かしてみた
Flue 1.0 BetaのAgent・Skill・Workflowを使い、GitHub Issueのseverity、再現可否、ラベル候補を構造化して返すトリアージエージェントを作った検証ログ。

Flueの全体像は、先に以下の記事で整理しています。
Flueを触る前に、まず何のフレームワークなのかを整理した https://llm-lab.dev/posts/flue-framework-overview/
前回、以下に記事を書きました。
Flue 1.0 Betaを軽く触ってQuickstartの一文でいきなり止まった話 https://llm-lab.dev/posts/flue-1-0-beta-local-check/
前回はQuickstartを追い、サンプルをビルドして、APIキーがない状態でエラーが出るところまで確認しました。今回はもう少し踏み込み、実際にモデル呼び出しまで通る小さなAgentを作りました。
作ったのは、GitHub Issueのタイトルと本文を受け取り、severity、再現可否、ラベル候補、要約を返すトリアージ用Agentです。GitHub webhookやコメント投稿までつなぐと記事の論点が広がりすぎるため、今回はFlueのAgent、Skill、Workflow、structured outputがどう動くかに絞っています。
ただし、完全に手入力だけだとGitHub Issueトリアージと呼ぶには少し遠いので、最後にGitHub CLIで実Issueを1件取得し、同じWorkflowへ渡す薄いスクリプトも用意しました。webhook常駐サーバーではなく、gh issue viewでtitle/bodyを取り出してflue runへ渡すだけの構成です。
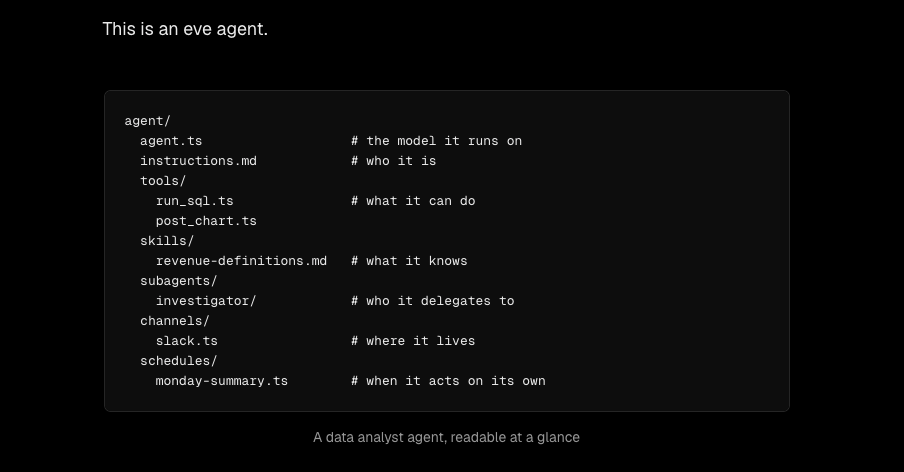
何を作ったか
プロジェクトは、Flueの規約に合わせてsrc/agents、src/skills、src/workflowsを分ける最小構成にしました。最終的なファイル構成は次の通りです。
scripts/
└─ triage-github-issue.mjs # GitHub CLIからIssueを1件取得する補助スクリプト
src/
├─ agents/
│ └─ issue-triage.ts # トリアージを行うAgent本体
├─ skills/
│ └─ triage/
│ └─ SKILL.md # トリアージの判定基準
├─ workflows/
│ └─ triage-issue.ts # 1件のIssueを分類するWorkflow
├─ providers.ts # OpenAI互換APIを使うためのprovider設定
└─ app.ts # dev server用のHono app今回の検証では、継続的に会話するAgentだけではなく、1件のIssueを受け取って結果を返す有限の処理を試したかったため、Agentに加えてWorkflowを作りました。Flueの整理で言えば、Agentは振る舞いやSkillを持つ主体で、Workflowはそれを使って一回の処理を完了させる入口です。
Skillを書く
まず、トリアージの判断基準をSkillとして切り出しました。FlueのSkillはMarkdownで書けるため、コードに埋め込むよりも判断基準を見直しやすくなります。
---
name: triage
description: Triages a GitHub issue by severity and reproducibility, and proposes labels.
---
# Issue Triage
Read the issue title and body provided in the prompt. Decide:
1. `severity`: one of `low`, `medium`, `high`, `critical`.
2. `reproducible`: whether the report includes enough information to reproduce the problem.
3. `labels`: an array of suggested GitHub labels.
4. `summary`: a one-paragraph summary in Japanese.
Be conservative. Do not guess at reproduction steps, affected users, system state, or business impact that are not present in the issue body.ここで意識したのは、Issue本文に書かれていない影響範囲や再現条件を推測させないことです。トリアージは分類タスクに見えますが、実際には入力にない情報を補いたくなる場面が多いので、「保守的に判断する」という制約を明示しました。
Agentを書く
Agent本体はsrc/agents/issue-triage.tsに置きました。
import '../providers';
import { createAgent } from '@flue/runtime';
import triage from '../skills/triage/SKILL.md' with { type: 'skill' };
export const description = 'Triages a GitHub issue by severity, reproducibility, and labels.';
export default createAgent(() => ({
model: process.env.FLUE_MODEL ?? 'openai/preview/Kimi-K2.6',
skills: [triage],
instructions:
'You triage incoming GitHub issues. Use the triage skill to classify severity, reproducibility, and suggested labels. Be conservative: never assume reproduction steps or impact that are not written in the issue body.',
}));前回のQuickstartではanthropic/claude-sonnet-4-6のようにモデルを固定していましたが、今回は手元で利用できるOpenAI互換APIを使いました。記事の主題はFlueの検証なので、特定providerの話は前面に出しません。重要なのは、Flue側ではprovider-id/model-id形式のmodel specifierを使い、必要に応じてprovider設定を差し替えられるという点です。
OpenAI互換APIを使う場合は、registerProvider()で組み込みopenai providerの向き先を変えています。
import { registerProvider } from '@flue/runtime';
const openAiCompatibleApiKey = process.env.OPENAI_COMPAT_API_KEY;
const openAiCompatibleBaseUrl = process.env.OPENAI_COMPAT_BASE_URL;
if (openAiCompatibleApiKey && openAiCompatibleBaseUrl) {
registerProvider('openai', {
baseUrl: openAiCompatibleBaseUrl,
apiKey: openAiCompatibleApiKey,
models: {
'gpt-oss-120b': {
contextWindow: 131_072,
maxTokens: 16_384,
},
'preview/Kimi-K2.6': {
contextWindow: 131_072,
maxTokens: 16_384,
},
},
});
}このあたりで一度失敗したのは、独自のprovider IDを作ろうとしたことです。sakura/example-modelのような独自prefixを登録すればよいと考えましたが、flue runではモデル解決のタイミングにうまく乗らず、Unknown model specifierで止まりました。最終的には、OpenAI互換APIとして扱うなら、組み込みのopenai providerをbase URL差し替えで使う方が素直でした。
Workflowを書く
1件のIssueを入力として受け取り、Agentを初期化して結果を返すWorkflowを作りました。
import '../providers';
import { type FlueContext, type WorkflowRouteHandler } from '@flue/runtime';
import * as v from 'valibot';
import issueTriage from '../agents/issue-triage';
type IssuePayload = {
title: string;
body: string;
};
const TriageResult = v.object({
severity: v.picklist(['low', 'medium', 'high', 'critical']),
reproducible: v.boolean(),
labels: v.array(v.string()),
summary: v.string(),
});
export const route: WorkflowRouteHandler = async (_c, next) => next();
export async function run({ init, payload }: FlueContext<IssuePayload>) {
const harness = await init(issueTriage);
const session = await harness.session();
const { data } = await session.prompt(`Use the triage skill to classify this GitHub issue.
Title:
${payload.title}
Body:
${payload.body}
Return only the structured triage result.`, {
result: TriageResult,
});
return data;
}ここではValibotで結果スキーマを定義しています。Issueトリアージのような後続処理につなげるタスクでは、自然文のまま返すより、severityやlabelsを型付きで受け取れる方が扱いやすくなります。
まずpayloadを直接渡して動かす
.envは次のように、OpenAI互換APIとして抽象化した名前にしています。
OPENAI_COMPAT_API_KEY="your-api-key"
OPENAI_COMPAT_BASE_URL="https://your-openai-compatible-endpoint/v1"
FLUE_MODEL="openai/preview/Kimi-K2.6"FLUE_MODELは必ずprovider-id/model-id形式で書きます。OpenAI互換APIの向き先を差し替えている場合でも、Flue上のprovider IDはopenaiなので、preview/Kimi-K2.6ではなくopenai/preview/Kimi-K2.6になります。
最初はGitHubには接続せず、Issueのtitleとbodyを直接payloadとして渡してWorkflowを確認します。ここで見たいのは、GitHub連携ではなく、Agent、Skill、Workflow、structured outputの中核処理が最後まで通るかです。
npm run triage -- '{"title":"Dashboard is blank after login","body":"Steps: log in, open /dashboard. Expected widgets. Actual blank white screen in Chrome 126."}'最終的に、次のような結果が返りました。
▗ flue run
▚ workflow triage-issue
▘ starting...
run run_01KVE99X9K35SVM9ZJ14NHV0YB
thinking
The user wants me to triage a GitHub issue using the triage skill...
tool activate_skill
tool done activate_skill (547 chars)
tool finish
tool done finish
{
"severity": "high",
"reproducible": true,
"labels": [
"bug",
"frontend",
"dashboard"
],
"summary": "ログイン後に /dashboard を開くと、ウィジェットが表示されるべきところが空白の白い画面が表示される。Chrome 126 で発生したバグ。"
}
done workflow completedtool activate_skillでSkillが読み込まれ、最後にtool finishでValibotのスキーマに合う結果が返っています。このログを見ると、Flueが単にプロンプトを投げているだけではなく、Agentの実行をツール呼び出しと完了条件を持つプロトコルとして扱っていることが分かります。
次にGitHub Issueを1件だけ読む
中核処理が動くことを確認した後で、GitHub CLIで実Issueを1件だけ取得する入口を足しました。ここでもGitHub webhookまでは作らず、gh issue viewで取得したtitleとbodyを、先ほどと同じWorkflowへ渡します。
import { execFileSync, spawnSync } from 'node:child_process';
const [, , repo, issueNumber] = process.argv;
if (!repo || !issueNumber) {
console.error('Usage: npm run triage:github -- owner/repo issue-number');
process.exit(1);
}
const issueJson = execFileSync(
'gh',
['issue', 'view', issueNumber, '--repo', repo, '--json', 'title,body,url,number'],
{ encoding: 'utf8' },
);
const issue = JSON.parse(issueJson);
const payload = JSON.stringify({
title: issue.title,
body: issue.body ?? '',
source: {
repo,
number: issue.number,
url: issue.url,
},
});
const result = spawnSync(
'npx',
['flue', 'run', 'triage-issue', '--target', 'node', '--payload', payload],
{ stdio: 'inherit' },
);
process.exit(result.status ?? 1);使い方は次の通りです。
gh auth login
npm run triage:github -- owner/repo 123owner/repoは対象リポジトリのフルネーム、123はIssue番号です。たとえばwithastro/astroのIssue 1を読む場合は、次のように指定します。
npm run triage:github -- withastro/astro 1この方法なら、GitHub webhookの署名検証、常駐サーバー、コメント投稿権限、ラベル更新権限をいったん考えずに、実Issueの本文をFlueのWorkflowへ流せます。今回確認したかった中核は「Issueを読んだ後の分類処理」なので、最初のGitHub連携としてはこのくらいの薄さで十分でした。
実際にwithastro/astroのIssueを1件読ませると、次のようにWorkflowが完了しました。
$ npm run triage:github -- withastro/astro 1
▗ flue run
▚ workflow triage-issue
▘ starting...
run run_01KVEAEZ5RMQVYFRACSBMFT79J
tool activate_skill
tool done activate_skill (547 chars)
tool finish
tool done finish
{
"severity": "low",
"reproducible": false,
"labels": [
"enhancement"
],
"summary": "本Issueは、開発時にファイル変更を自動的に検知してコンパイルする`npm run dev`モード(ウォッチモード)を追加する機能要請である。記載内容は要望の主旨のみに留まっており、具体的な実装方法、対象とするビルドツール、既存ワークフローへの影響などの詳細情報は含まれていない。"
}
done workflow completedここまで来ると、少なくとも「GitHub上の実Issueを読み、FlueのWorkflowで分類し、構造化結果として返す」ところまでは確認できたと言えます。まだGitHubへコメントを書き戻してはいませんが、Issueを読む部分とトリアージ中核処理はつながりました。
詰まったところ
今回一番時間を使ったのは、API接続そのものよりも、モデルがFlueの実行プロトコルにどれだけ従えるかでした。
最初に試したモデルでは、API接続とモデル呼び出し自体は通っていました。しかし、Workflowの最後で必要なfinish tool callを返せず、次のエラーで止まりました。
Error: Workflow failed: [internal_error] The agent gave up: Agent did not call `finish` or `give_up` after 33 attempts.ログを見ると、モデルは「finishを呼ぶ必要がある」と文章では理解しているものの、実際のtool callとして返せていませんでした。これはFlueの問題というより、モデル側のtool calling適性やOpenAI互換API側の実装差が表に出たものだと見ています。
同じWorkflowでも、別のモデルに切り替えるとactivate_skillからfinishまで進み、Workflowは完了しました。ここから分かるのは、Agentフレームワークの検証では「APIが呼べるか」だけでなく、「モデルがフレームワークの期待するtool callingやstructured outputのプロトコルを守れるか」を確認する必要があるということです。
まだやっていないこと
今回の記事では、GitHub webhookを受け取るChannel、GitHubへのコメント投稿、OpenTelemetryへのexportまでは実装していません。最初はそこまで一気に試すつもりでしたが、実際にはAgent、Skill、Workflow、model provider、structured outputだけでも十分に確認することがありました。
特に、未信頼のGitHub Issue本文を扱う場合、local()サンドボックスを安易に使うべきではありません。リポジトリのファイルを読ませたい、CLIを叩かせたい、GitHub tokenを使わせたい、といった欲求は自然に出ますが、その時点で「どの入力を信頼しているのか」「どの環境変数をAgentに見せるのか」という境界設計が必要になります。
次にやるなら、GitHub Actions上でflue runを呼び、Issue本文をpayloadとして渡す構成を試します。常駐サーバーで外部webhookを受けるよりも、まずはCIの使い捨て環境で動かす方が、検証としては扱いやすそうです。
まとめ
今回の検証で確認できたのは、FlueではAgentの振る舞いをSkillとして分け、WorkflowからAgentを初期化し、Valibotで構造化結果を受け取れるという点です。Issueトリアージのような「入力を分類し、後続処理に渡す」タスクとは相性がよいと感じました。
一方で、Agentフレームワークはモデルを差し替えれば同じように動く、というほど単純ではありません。特にtool callingやstructured outputを前提にする場合、モデルがプロトコルに従えるかどうかが実行成否に直結します。今回のように、あるモデルではfinishを返せず失敗し、別モデルでは同じWorkflowが完了する、という差は普通に起きます。
その意味で、Flueの検証では、コードがビルドできるか、APIキーが通るか、モデルが返答するか、Workflowが完了条件まで到達するかを分けて見る必要があります。ここを分けてログに残しておくと、単なる「動いた・動かなかった」ではなく、Agent実装時にどの層で問題が起きたのかを説明しやすくなります。