VercelのEveでツール付きエージェントを組んで、TUIから動かしてみた
前回の軽い検証の続きとして、Eveにツールとevalを足し、Vercel AI Gateway経由のモデル設定、TUIでのツール呼び出し、infoやevalまわりを確認した実装ログ。

Eveの全体像は、先に以下の記事で整理しています。
VercelのAIエージェントFW「eve」を導入前に調査したメモ https://llm-lab.dev/posts/eve-vercel-agent-framework-survey/
前回、以下の記事を書きました。
VercelのエージェントフレームワークEveをちょっと触ってみた https://llm-lab.dev/posts/vercel-eve-first-look/
ローカルのdevサーバーが立ち上がるところまでは確認できていたので、今回はその続きとして、ツールを実際に書いて動かし、TUIからモデル設定とツール呼び出しまで確認しました。
最初はHTTP APIとバックグラウンド起動で確認しようとしていましたが、実際にはEveのTUIで/modelからVercel AI Gateway側のモデルを選び、そのまま会話するのが一番素直でした。今回はanthropic/claude-haiku-4.5へ切り替え、ダミーの天気ツールが呼ばれるところまで確認しています。
作ったもの
前回作った最小プロジェクトに、天気を返すダミーツールを1本追加しました。
// agent/tools/get_weather.ts
import { defineTool } from "eve/tools";
import { z } from "zod";
export default defineTool({
description: "Get the current weather for a city. Returns dummy data for local testing.",
inputSchema: z.object({
city: z.string().describe("City name, e.g. Tokyo"),
}),
async execute({ city }) {
return {
city,
temperatureC: 26,
condition: "partly cloudy",
note: "this is dummy data from a local check, not a real weather API",
};
},
});ファイル名がそのままツール名になり、instructions.mdで「天気を聞かれたらこのツールを使う」と一言加えるだけで、登録のための配線作業は一切不要でした。Flueでも似た規約はありましたが、Eveはagent/tools/という1階層だけのフラットな規約で、ディレクトリを掘る必要すらない点がさらに単純です。
# Identity
You are a helpful assistant for local framework testing.
- When asked about weather, use the get_weather tool rather than guessing.
- Answer concisely.evalも1本足しました。
// evals/weather.eval.ts
import { defineEval } from "eve/evals";
import { includes } from "eve/evals/expect";
export default defineEval({
description: "The assistant uses get_weather and reports the dummy Tokyo weather result.",
async test(t) {
await t.send("東京の天気を教えてください");
t.completed();
t.calledTool("get_weather", { output: { city: "Tokyo", condition: "partly cloudy" } });
t.check(t.reply, includes("26°C"));
t.check(t.reply, includes("ダミー"));
},
});最初はt.check(t.reply, includes("partly cloudy"))にしていましたが、実行してみるとツール出力のconditionはpartly cloudyでも、最終返答では「曇りのち晴れ」のように日本語へ言い換えられました。そのため、conditionはt.calledTool(...)の出力条件で確認し、ユーザー向け返答では26°Cや「ダミー」のように実際に出てくる文言を見る形に変えています。
t.calledTool(...)でツール呼び出し自体をアサーションにできるのは、ユニットテストとE2Eテストの間を埋める書き味で、地味に使いやすそうだと感じました。一方で、自然言語の最終返答に英語のツール値がそのまま出るとは限らないので、何をツール出力で見るか、何を返答文で見るかは分けたほうが安定します。
TUIからモデルを変更して動かす
npm exec -- eve devでTUIを起動し、まず/modelを実行しました。ここでモデルをanthropic/claude-haiku-4.5へ変更すると、次のプロンプトからそのモデルが使われます。
▌ /model
⎿ Model changed to anthropic/claude-haiku-4.5. Live on your next prompt.そのまま天気を聞くと、Eveはget_weatherツールを呼び出し、ツール結果を読んで日本語で返答しました。
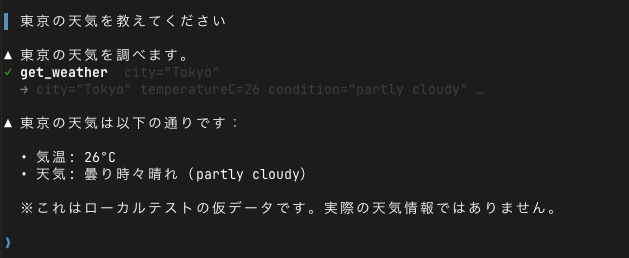
▌ 東京の天気を教えてください
▲ 東京の天気を調べます。
✓ get_weather city="Tokyo"
→ city="Tokyo" temperatureC=26 condition="partly cloudy" …
▲ 東京の天気は以下の通りです:
• 気温: 26°C
• 天気: 曇り時々晴れ(partly cloudy)
※ これはローカルテストの仮データです。実際の天気情報ではありません。ここで確認できたのは、agent/tools/get_weather.tsというファイル配置だけでツールが検出され、モデル側から自然に呼び出されることです。ツール登録のための明示的な配列やルーティングコードは書いていません。
ビルドは素直に通った
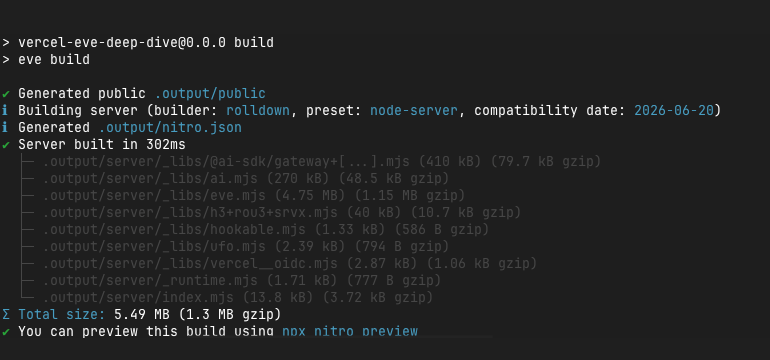
eve buildを叩くと、Nitroベースのサーバーが構築されました。
[nitro] √ Building server (builder: rolldown, preset: node-server, ...)
├─ .output/server/_libs/@ai-sdk/gateway+[...].mjs (409 kB)
├─ .output/server/_libs/ai.mjs (270 kB)
├─ .output/server/_libs/eve.mjs (4.67 MB)
...
[BUILD] built output at /path/to/my-agent/.output@ai-sdk/gatewayが最初からバンドルされている構成から分かるように、EveはモデルプロバイダーへのアクセスをVercel AI Gateway経由に統一する前提で作られています。Anthropic直叩きの選択肢自体はanthropic/claude-sonnet-4-6のような文字列で指定するだけに見えますが、実体としてはAI Gatewayが間に入る構成です。これは後段の詰まりの原因にもつながるので、覚えておく価値がありました。
バックグラウンドプロセスの管理で踏んだ小さな罠
ここは本題から少し外れますが、実装検証として書いておきます。eve devを何度か再起動する過程で、nohup ... &の素朴な書き方ではプロセスが数秒で消えてしまい、curlがConnection refusedを返す現象に複数回遭遇しました。setsidでセッションから切り離す形に変えたところ安定して動くようになりました。CLIツールをバックグラウンドで動かして検証する際は、シェルのジョブ管理がどう振る舞うかも合わせて見ておく必要があると再認識しました。
AI_GATEWAY_API_KEYを設定してTUIで進める
Eveの文字列モデルID、たとえばanthropic/claude-haiku-4.5はVercel AI Gateway経由で解決されます。そのためローカルで動かすには、Vercel AI GatewayのAPIキーを.env.localに置きます。
AI_GATEWAY_API_KEY="..."この状態でnpm exec -- eve devを起動し、TUI上で/modelを使うと、モデル変更と次の会話がその場で試せます。今回の検証では、anthropic/claude-haiku-4.5へ切り替えたあと、天気質問からget_weather呼び出しまで通りました。
HTTP APIを直接叩く方法もありますが、初回検証ではTUIのほうがモデル設定、ツール呼び出し、応答の流れをまとめて見られるので扱いやすいです。スクリーンショットを残すなら、/model後のモデル変更表示と、get_weatherが呼ばれた会話部分を撮っておくのがよさそうです。
エラーペイロードから見えた、組み込みツールの全体像
TUIでget_weatherの呼び出しが見えたので、次に気になったのは、Eveのエージェントが自作ツール以外にどんな組み込みツールを持っているのかです。ドキュメントとコンパイル結果を照らすと、自分で定義したツールのほかに、次のような標準ツール群が用意されています。
自分で定義したget_weather以外に、次のツールが最初から組み込まれていました。
| ツール名 | 役割 |
|---|---|
ask_question | ユーザーに選択肢付きの質問をして応答を待つ |
bash | サンドボックス内でシェルコマンドを実行する |
glob | パターンでファイルを検索する |
grep | ファイル内容を正規表現で検索する |
read_file | ファイルを読む |
write_file | ファイルを書く(既存ファイルは事前に読んでいないと失敗する制約付き) |
todo | セッション内のタスクリストを管理する |
web_fetch | URLを取得してmarkdown/text/htmlに変換する |
web_search | Anthropic提供のweb検索(type: providerとして実装) |
load_skill | 利用可能なSkillの全文指示を読み込む |
特にbash・read_file・write_file・glob・grepがデフォルトで揃っている点は、ブログ記事中で紹介されていた「エージェントに自分のコードを書かせて実行させる」という機能(write_file analysis/by_region.pyからのbash python analysis/by_region.pyという例)が、特別な設定なしに最初から有効になっていることを意味します。Flueではsandbox: local()のように明示的にサンドボックスを選択する一手間がありましたが、Eveでは「サンドボックス付きの汎用エージェント」がデフォルトの形のようです。
これは裏を返すと、セキュリティ上の前提がFlueとは異なるということでもあります。ブログ記事の説明によれば、Eveのサンドボックスは「ハーネスとは別のセキュリティコンテキストで動く分離環境」で、デプロイ時はVercel Sandbox、ローカルではDocker・microsandbox・just-bashのいずれかをアダプタとして使う設計です。つまりbashツールが最初から生えていても、その実行先はアプリケーションランタイムそのものではなく、隔離された別環境だという前提に立っています。Flueのlocal()が「ホストに直接アクセスする、信頼済み環境専用の選択」だったのに対し、Eveは「最初から隔離環境ありき」で組み込みツールを太くしている、という設計思想の違いが見えたのは、今回の収穫の一つでした。
とはいえ、今回の検証で実際に呼び出したのは自作のget_weatherだけです。bashやwrite_fileのような組み込みツールが、ローカル環境でどのサンドボックスバックエンドに乗ってどう実行されるかまでは、別途確認する必要があります。
evalコマンドにも設定ファイルが要る
eve evalを試したところ、こちらでも一段階の詰まりがありました。
Missing required eval config at evals/evals.config.ts.
Create it with defineEvalConfig({}) (optionally `{ judge: { model } }` to set
the default judge model for `t.judge.*` assertions).t.check(t.reply, includes(...))のような決定的なアサーションだけでなく、t.judge.*というLLM-as-judge的なアサーションも用意されているらしく、その既定のジャッジモデルを指定する場所にもなる、という構成のようです。まずはdefineEvalConfig({})だけを置けば、今回のような決定的なevalは書き始められます。
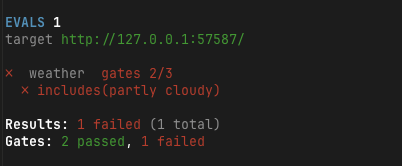
実際に一度走らせると、completedとcalledTool(get_weather)は通った一方で、includes(partly cloudy)だけ落ちました。これはツール出力にはpartly cloudyが入っているものの、最終返答ではモデルが日本語に言い換えたためです。evalを書くときは、内部の構造化出力を検証するのか、ユーザーに返る自然文を検証するのかを分けて考える必要があります。
期待値を分けたあとに再実行すると、4つのgateがすべて通りました。
✓ weather gates 4/4
Results: 1 passed (1 total)
Gates: 4 passed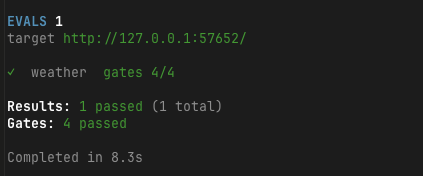
info コマンドで見えた内部構造
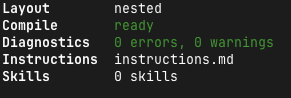
最後にeve infoで、コンパイル後の内部状態を確認しました。
Application
App Root /path/to/my-agent
Agent Root /path/to/my-agent/agent
Layout nested
Compile ready
Diagnostics 0 errors, 0 warnings
Instructions instructions.md
Skills 0 skills
Artifacts
Compiled Manifest .eve/compile/compiled-agent-manifest.json
Discovery Manifest .eve/discovery/agent-discovery-manifest.json
...
Messaging
Create POST /eve/v1/session
Continue POST /eve/v1/session/:sessionId
Stream GET /eve/v1/session/:sessionId/streamSkills 0 skillsという表示から、ツール(tools/)とSkill(skills/)はEve内部でも別カウントの管轄になっていることが分かります。今回はSkillを1つも作っていなかったので、これは整合した結果でした。また、コンパイル結果がJSON manifestとして.eve/配下に永続化される作りも、Flueのビルド時マニフェストに近い発想です。エージェントのファイル構成という宣言的な情報源から、実行用の構造化データを生成する、というパターンは、この世代のエージェントフレームワークでかなり共通している感触があります。
まとめ
今回の検証で分かったことは次の3つでした。
- TUIでの確認が一番素直:
npm exec -- eve devから/modelでモデルを変え、そのまま会話すると、モデル変更とツール呼び出しの流れを見やすい。 - ファイル配置だけでツールが生える:
agent/tools/get_weather.tsを置き、instructionsで使う方針を書くだけで、get_weatherがモデルから呼ばれた。 - evalには設定ファイルが要る:
defineEvalConfig({})を伴うevals.config.tsがないとeve evalが動かない。最初の1本でも設定ファイルを書く一手間は発生する。
bash・read_file・write_fileを含む実行能力が最初から太く組み込まれている設計は、Flueの「サンドボックスは明示的に選ぶもの」という設計とは対照的です。どちらが良いという話ではなく、デフォルトの安全側の置き方が違う、というのが今回得られた一番の所感です。
次に試すとしたら、bashツールを実際に使ったコード生成・実行のデモ、t.judge.*を使ったeval、Slackチャンネルの実連携まで進めてみたいと思っています。Slack連携は今回は未検証なので、別の記事として分けたほうがよさそうです。
