Langfuse Assistantは運用調査の入口になるかをAPIの正解データで検証する
Langfuse AssistantのPublic Betaを、既存のSakana Fugu観測データとPublic APIから計算した正解値で検証します。

LangfuseにTraceを貯めても、障害調査のたびにフィルター、時間範囲、集計軸を組み立てる作業は残ります。ダッシュボードがあることと、必要な事実へすぐ到達できることは別問題です。
2026年6月19日、LangfuseはLangfuse AssistantのPublic Betaを公開しました。Trace、Observation、Metricsについて自然言語で質問でき、Langfuse CloudではFeature Previewへの参加なしで利用できると説明されています。
これは便利そう!!
ただし、運用調査で重要なのは「それらしい要約が返ること」ではなく、期間、対象、集計方法を正しく解釈し、元データと一致する答えを返すことです。
そこで本記事では、以前Sakana Fugu APIをLangfuseで観測したときのTraceを使い、Assistantの検索と集計がPublic APIから計算した正解値に一致するかを確認しました。主題はFuguの再評価ではなく、Langfuse Assistantが既存の観測データをどこまで正確に読めるかです。
検証元のデータと当時の観測結果は、次の記事にまとめています。
Sakana Fugu APIをLangfuseで観測し、マルチエージェントの見えないコストを考える FuguのLevel 1〜3を実行し、レイテンシ、token、TTFTをLangfuseで観測した検証記事。 https://llm-lab.dev/posts/sakana-fugu-langfuse-experiment/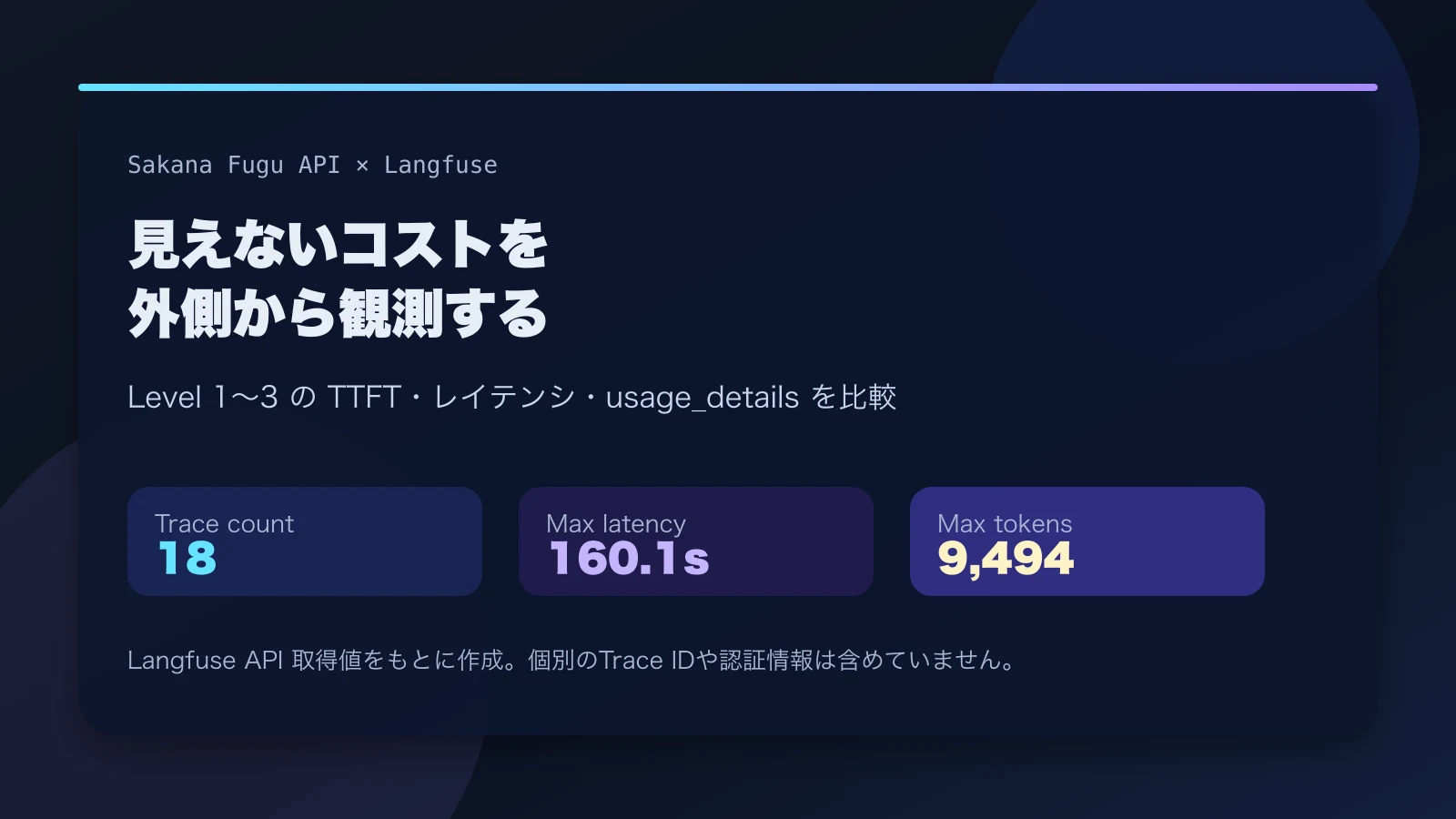

Langfuse Assistantは何をしているのか
公式説明によると、AssistantはLangfuse MCP Serverを基盤にしています。自然言語の質問を受けると、MCP toolsを使ってTrace、Observation、Metricsを照会し、その文脈に沿って回答します。
自然言語の質問
↓
Langfuse Assistant
↓
Langfuse MCP Serverのtools
↓
Trace / Observation / Metrics
↓
文脈付きの回答つまり、単にダッシュボードの説明を返すチャットではなく、プロジェクト内の観測データを照会するAgentに近い構成です。公式ページでは、次のような質問例が示されています。
- 前日にレイテンシが高かったTraceはどれか
- 直近1時間に失敗したGenerationを表示できるか
- 今週のtoken消費をモデル別に分解できるか
Public BetaはLangfuse Cloud限定で、Beta期間中は無料です。将来の価格は変更される可能性があります。また、基盤となるLangfuse MCP Serverには読み取りと書き込みのtoolsがあり、外部MCP clientで利用する場合は、必要に応じてallowlistで書き込み操作を制限する設計が必要です。Assistant本体がどのtoolsを許可しているかは、公開された変更履歴だけでは判断できません。
Assistantを有効化するときには、組織でAI featuresを有効にし、データが処理のために利用中のリージョンにあるAWS Bedrockへ送られる可能性があるという確認ダイアログが表示されました。観測データにはprompt、completion、metadataが含まれ得るため、便利さだけで有効化せず、組織のデータ取り扱いルールと対象リージョンを確認すべきです。
検証で確かめたいこと
自然言語で質問できること自体は、公式デモを見れば分かります。今回確かめたいのは、その先です。
| 質問 | 確認する論点 |
|---|---|
| Fuguの高レイテンシ上位5件 | Observation名、降順、レイテンシ、時刻 |
| 非ストリーミングのLevel別token | Level 1〜3の分類、件数、input・output・total |
| streamとnonstreamのusage差 | 名前による分類、件数、total tokenの集計 |
特に注意したいのは、yesterday や this week が一意ではない点です。利用者のタイムゾーン、プロジェクトの設定、UTCのどれを使うかによって対象データが変わります。答えの文章が自然でも、時間範囲が違えば運用上は誤答です。
APIから正解データを作る
比較用に、Fugu実験で使用したLangfuseプロジェクトのObservations一覧を読み取り、質問ごとの期待値を計算する検証スクリプトを用意しました。これはLangfuse公式CLIではなく、本記事の検証用に作成した読み取り専用スクリプトです。新しいTraceは送信せず、既存Fugu Observationの件数、順序、レイテンシ、tokenを集計します。
node scripts/build-ground-truth.mjs対象期間はFugu実験が記録されている2026年6月22日22時30分から23時45分までのUTCに固定しました。出力には質問文だけでなく、計算に使ったfromとtoも保存します。
API側の期待値は次のようになりました。
| 検証項目 | APIから計算した期待値 |
|---|---|
| 高レイテンシ上位 | Level 3の4件が上位を占め、最長はlevel3-stream-1の160.096秒 |
| 非ストリーミングのLevel別token | Level 1は1,360、Level 2は4,581、Level 3は17,111 token |
| streamとnonstreamのusage差 | 各8件。streamは0、nonstreamは23,052 token |
この値は、Fuguへ実際にLevel 1〜3のプロンプトを送ったときの観測結果です。既存記事ではLevel 3でレイテンシとtokenが跳ね、ストリーミングObservationのusageが0になることを確認していました。Assistantが同じ傾向だけでなく具体的な件数と値まで取り出せるかを見ます。
Assistantへ同じ条件で質問する
API側の正解データを作った後、Assistantにも期間とタイムゾーンを明示して質問しました。曖昧なyesterdayやthis weekをそのまま使わず、API集計と同じUTCの絶対時刻を指定しています。
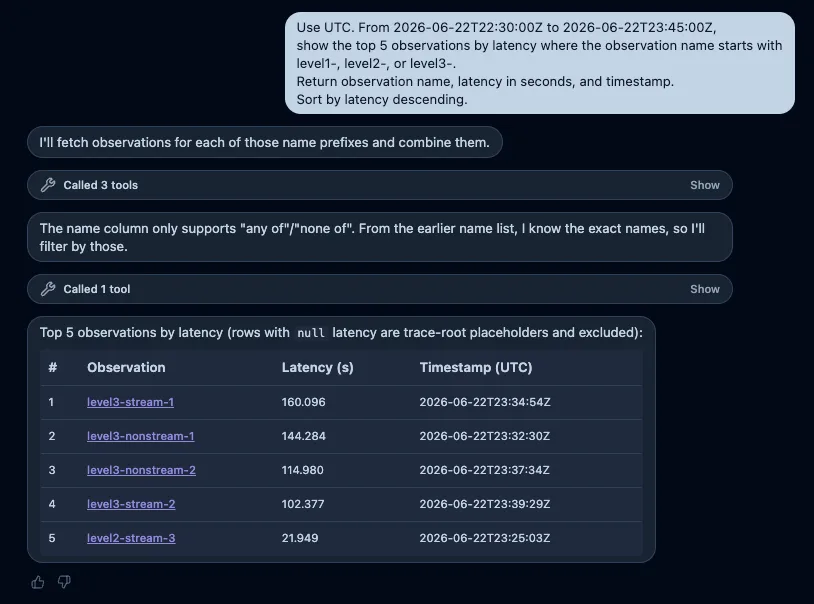
高レイテンシ上位5件
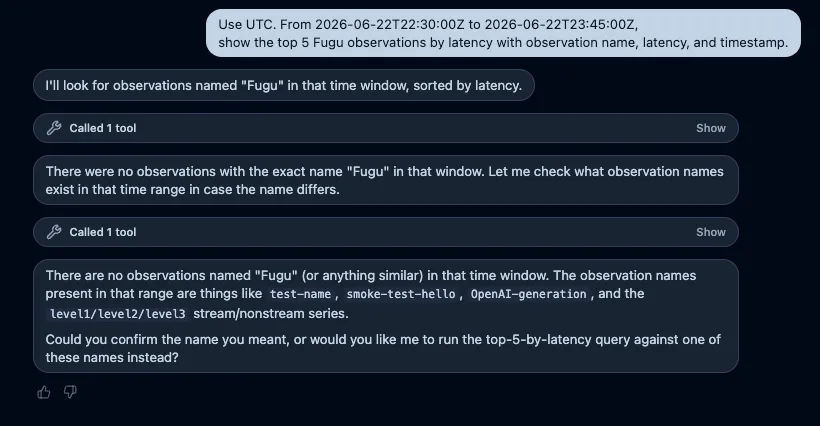
Use UTC. From 2026-06-22T22:30:00Z to 2026-06-22T23:45:00Z,
show the top 5 Fugu observations by latency with observation name, latency, and timestamp.最初はこの質問で取得できると思っていました。しかしAssistantはFuguを実験全体を表す業務上の呼び名ではなく、Observation名の検索条件として解釈しました。その結果、Fuguという名前のObservationはないとして0件を返し、同じ期間にsmoke-test-helloやlevel1-*からlevel3-*があることを案内しました。
これは単純な失敗ではありません。Assistantは存在しないデータを作らず、実際に存在するObservation名を確認して、条件の修正を求めています。一方で、利用者が「Fugu実験」と呼んでいる単位と、Langfuse上のObservation名は自動的には結び付きませんでした。
そこで、対象をデータモデル上の名前へ落として再質問します。
Use UTC. From 2026-06-22T22:30:00Z to 2026-06-22T23:45:00Z,
show the top 5 observations by latency where the observation name starts with
level1-, level2-, or level3-.
Return observation name, latency in seconds, and timestamp.
Sort by latency descending.API側では、level3-stream-1の160.096秒が最長で、Level 3の4件が上位4件を占めます。Assistantは最初に3つのprefixごとに検索を試みましたが、Observation名のfilterがany ofとnone ofに限られることを検出しました。その後、直前に取得した名前一覧から完全なObservation名へ置き換え、null latencyのTrace rootを除外して上位5件を返しました。
結果は、Observation名、順序、レイテンシ、timestampのすべてでAPI側の期待値と一致しました。prefix filterが直接使えなくても、利用可能なfilterと会話内で得た名前一覧を組み合わせて検索を完遂した点は、単純な自然言語からクエリへの変換以上の挙動です。
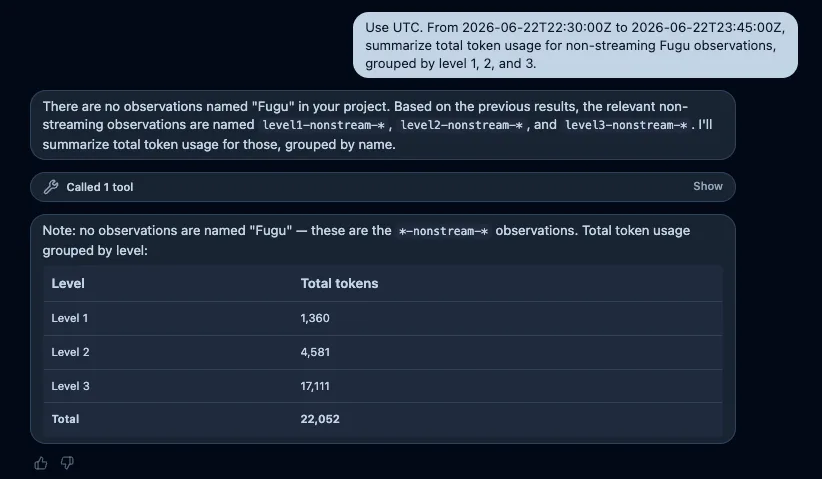
Level別のtoken消費
Use UTC. From 2026-06-22T22:30:00Z to 2026-06-22T23:45:00Z,
summarize total token usage for non-streaming Fugu observations,
grouped by level 1, 2, and 3.API側ではLevel 1が3件で1,360 token、Level 2が3件で4,581 token、Level 3が2件で17,111 tokenでした。AssistantはFuguという名前がないことを断ったうえで、会話内で判明していたlevel1-nonstream-*からlevel3-nonstream-*を対象に切り替え、Level別の3値を正しく返しました。
ところが、最後の総計は22,052 tokenと回答しました。3つを加算すると正しくは23,052 tokenです。個別集計はAPIと一致しているのに、最後の単純な加算で1,000 token落ちています。
そこを間違えるのか!!
この結果は、Assistantの回答を表の見た目だけで信じてはいけない理由を端的に示しています。検索とgroupingが正しくても、その後の回答生成で算術誤りが入る余地があります。運用判断へ使うなら、合計値をtool側で計算させるか、少なくとも構成値との整合を検査する必要があります。
ストリーミング側のusage欠落
Use UTC. From 2026-06-22T22:30:00Z to 2026-06-22T23:45:00Z,
compare token usage recorded for Fugu observations whose names contain stream and nonstream.
Report counts and total tokens for each group.API集計では、token-bearing Generationとして数えるとstreamとnonstreamは各8件で、total tokenはstreamが0、nonstreamが23,052でした。AssistantはObservation一覧上のplaceholder rowsも含めて各16件と数えましたが、「token-bearing generationsはその半分」と説明しています。したがって、実Generationの件数とtoken合計はAPI集計と一致しています。
この回答で重要なのは、単にstreamを0 tokenと表示しただけでなく、0になった理由としてstreaming時のusage取得設定を疑ったことです。以前のFugu検証でも、ストリーミングObservationのusageだけが0になることを確認していました。Assistantは既存データから同じ運用上の違和感を拾い、SDK設定の確認という次の調査へつなげました。
ただし、ここは「ストリーミングが無料」という意味ではありません。この計装経路ではstream側にusageが記録されていなかった、という観測結果です。また、placeholderをObservation countへ含めるかどうかで件数表記が変わるため、何を1件と数えたかを回答内で明示する必要があります。

APIの期待値と回答を比較する
3問の結果を比較すると、高レイテンシとstream/nonstreamの集計はAPIから計算した期待値と一致しました。Level別tokenは各Levelの値まで一致しましたが、最後の総計だけ誤りました。
| 検証項目 | APIの期待値 | Assistantの回答 | 判定 |
|---|---|---|---|
| 高レイテンシ上位5件 | 最長160.096秒、Level 3が上位4件 | 同じ順序と値 | 一致 |
| Level別token | 1,360 / 4,581 / 17,111、総計23,052 | Level別は一致、総計を22,052と誤答 | 部分一致 |
| stream / nonstream | 実Generationは各8件、0 / 23,052 token | placeholder込み各16 rows、実Generationは半分、token合計一致 | 一致 |
今回の検証では、検索対象のプロジェクトと、自然言語で呼ぶ実験名の二段階で詰まりました。Assistantは開いているプロジェクトの範囲で検索するため、プロジェクトが違えば結果は出ません。正しいプロジェクトを開いていても、Fuguのような業務上の呼び名がObservation名やmetadataへ明示的に対応していなければ、意図したfilterにはなりません。
ここはかなり実務的です。Assistantを便利にするには、質問を工夫するだけでなく、Observation名、metadata、tagを人間が呼ぶ単位に合わせて設計する必要があります。
運用ではAssistantを三段階に分けて使う
Assistantを運用へ入れるなら、用途を次の三段階に分けるのが現実的です。
探索
「昨日、どこが遅かったか」「失敗は増えたか」と尋ね、調査対象の候補を絞ります。この段階では、自然言語UIの速さが効きます。ダッシュボードの列やフィルターを覚えていない人でも、観測データへ入る導線を持てます。
確認
Assistantが示した期間、件数、モデル、単位を画面またはAPIで照合します。ゼロ件という回答も、単にデータがないのか、filterや期間解釈で落ちたのかを区別する必要があります。
自動化
定期通知、SLO判定、課金停止、再実行などは、自然言語回答ではなく、Monitors、Public API、固定したクエリへ寄せます。Assistantは対話的な探索には向きますが、同じ条件を継続評価する処理では再現性の高い仕組みを優先すべきです。
この役割分担は、以前作ったLangfuse朝ブリーフィングやMonitorsとも競合しません。Assistantは人が未知の異常を掘る入口、Monitorsは既知のしきい値を監視する仕組み、朝ブリーフィングは複数条件を決まった時間に要約する仕組みです。
Public Betaで見えた設計上の論点
実回答では正答かどうか以外に、次の点も確認しました。
- 回答に使用した期間とタイムゾーンを明示できること
- TraceとObservationを混同せず、質問した粒度で返せること
- tokenのinput、output、totalを同じ単位で示せること
- 該当データがない場合に、存在しない結果を生成しないこと
一方で、元データへ遷移できる識別子やリンクが常に返るか、同じ質問を繰り返したときに結果が安定するかは、継続して確認すべき論点です。
LLMOpsの調査支援Agentに必要なのは、もっともらしい解説力だけではありません。どのデータを、どの条件で、どう集計したかを人が追跡できることです。ここが見えれば、Assistantは「ダッシュボードの代わり」ではなく、「観測データへ入る新しいインターフェース」として評価できます。
まとめ
Langfuse AssistantのPublic Betaによって、Trace、Observation、Metricsを自然言語で探索できる入口がLangfuse Cloudに加わりました。基盤がLangfuse MCP Serverである点も、単なるヘルプチャットではなく、観測データをtools経由で扱う設計として興味深いところです。
一方で、運用判断へ使うなら、回答の流暢さではなく、期間、対象、集計方法、元データとの一致を評価する必要があります。今回固定した3問では、検索とgroupingはおおむねPublic APIの期待値と一致しましたが、最後の単純加算で誤答も出ました。この結果だけで任意の質問や大量データでも正確だとは言えません。したがって現時点の判断は、探索の入口としては使えるが、自動監視や確定判断を置き換える段階ではない、です。
Assistantの回答をAPIや固定クエリと照合できる状態にしておけば、「自然言語で聞けた」で終わらず、「どの条件なら運用調査に使えるか」まで判断できます。Public Betaを試す際は、まず曖昧な相対期間を避け、小さな正解データを用意してから評価するのが安全です。