Observing the Black Box of a Multi-Agent API with Sakana Fugu and Langfuse
I subscribed to Sakana Fugu to understand its nature as an OpenAI-compatible API and to plan how to observe its black-box cooperative reasoning from the outside.
I subscribed to Sakana Fugu, the new model from Sakana AI that has been getting attention. The goal of this article is not to evaluate Sakana Fugu’s performance at this point. What I want to see is how far I can trust and rely on an integrated API that bundles multiple models and roles for operations.
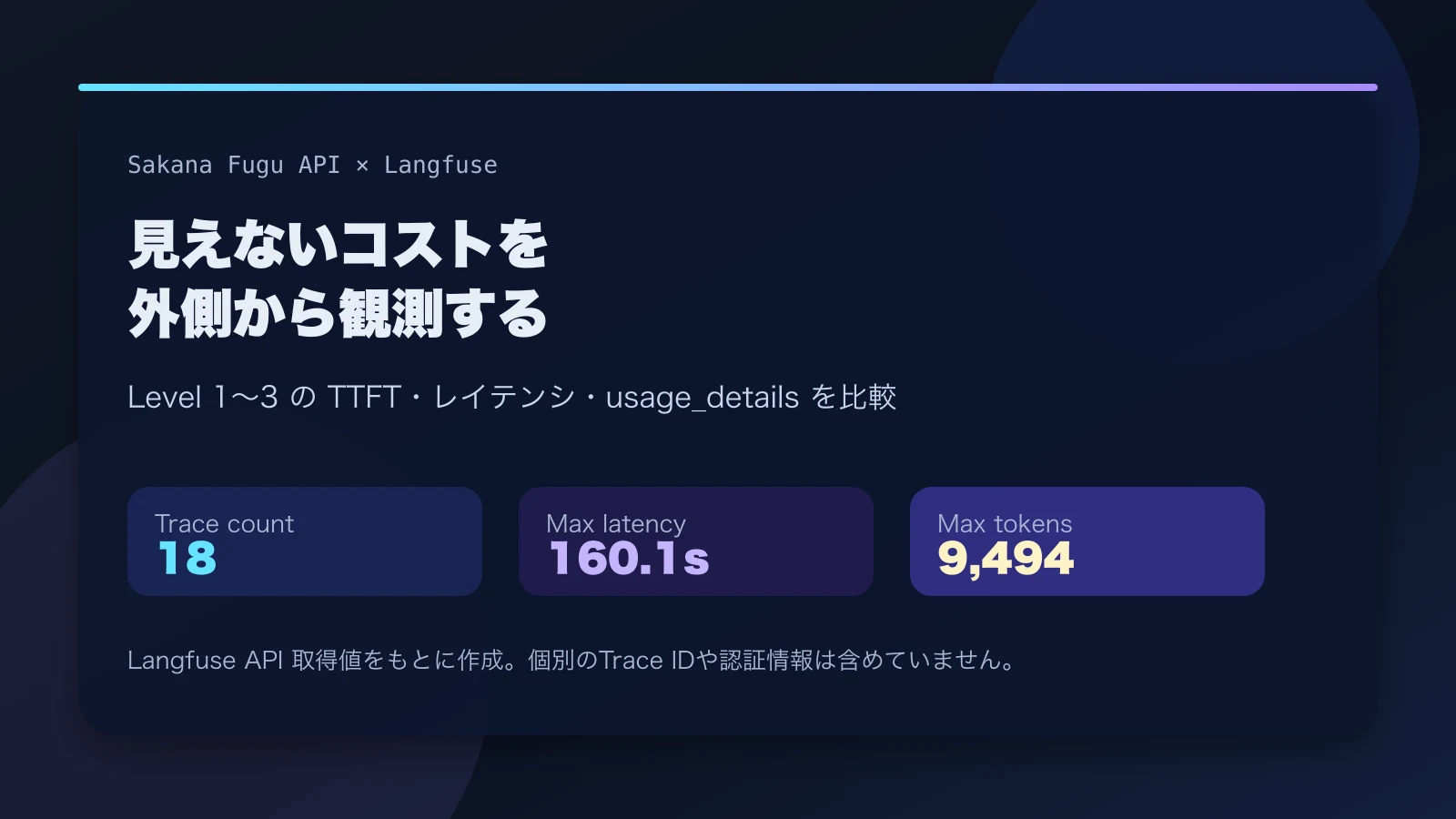
To that end, I will use Langfuse to observe not only Fugu’s responses but also TTFT, total latency, token volume, and variance on rerun, preparing to grasp the external shape of its black-box cooperative reasoning.
Sakana Fugu: A Single Model that Directs Multiple Agents https://sakana.ai/fugu/
What interests me is the black-box nature
The appeal of Fugu lies in its ability to solve complex tasks by using multiple models and roles, rather than simply throwing prompts at a single model. Public information describes task-dependent role allocation and cooperative reasoning as key concepts.
This direction is quite interesting. On the other hand, I am honestly quite interested in how much of the internal decision-making is visible.
When building an agent yourself, you design role separations like Thinker, Worker, and Verifier, and manage the input, output, and failure recovery for each step yourself. In contrast, with an integrated API like Fugu, you may be able to push that complexity to the other side of the API.
However, from an LLMOps perspective, this convenience raises other questions.
- Does even a simple question always trigger heavy cooperative processing?
- Do latency and token consumption only spike for complex tasks?
- When it fails, can traces of internal retries or verification loops be seen from the outside?
- Compared to a self-built agent, what should be entrusted and what should be controlled by oneself?
If the internal steps themselves do not appear in the API response, we can only estimate from information observable from the outside. This is where Langfuse comes in. What is visible is not the internal implementation itself, but clues necessary for operational decisions should be obtainable from latency, usage, failure rates, and variance on reruns.
Deciding which metrics to look at with Langfuse first
In this verification, I plan to flow requests to the Fugu API into Langfuse and record at least the following metrics in the same format.
| What to observe | Reason for observing |
|---|---|
| TTFT | Estimate the weight of internal preparation and routing from the time to the first token |
| Total latency | See how processing time changes between simple and complex tasks |
| Input/output token count | See how cooperative processing is reflected in external usage |
| Success rate | See if it breaks with structured output or constrained tasks |
| Variance on rerun | See if routing or quality wavers with the same input |
Because an integrated API may be making multiple internal decisions, evaluation based on a single experience alone can be skewed. It is necessary to separate input types and compare them with the same observation items.
Trying in three stages
First, I will divide tasks into three stages and submit them.
Level 1 is simple fact-checking. I will throw short questions with clear answers that do not require external tools, and establish a baseline for when it returns via the shortest path. Here, I am looking for unnecessary overhead rather than high reasoning ability.
Level 2 is logical reasoning. I will throw problems that organize multiple conditions, find contradictions in specifications, or involve short design judgments. Here, I will look at how TTFT and total latency grow. If internal deliberation or verification steps increase, the time usage should differ from that of simple questions.
Level 3 is a task that seems to require autonomous coordination. For example, I will throw inputs that simultaneously demand requirements organization, implementation policy, testing perspectives, and risk identification. Here, I will look not only at output quality but also whether token count, latency, and variance on rerun increase non-linearly.
What I want to see here is not to expose Fugu’s internal implementation. As an external user, I want to determine which types of work are cost-effective to entrust, and which work is better broken down as a self-built agent.
Comparison axis between self-built agents and integrated APIs
What I personally want to know most is where an integrated API like Fugu replaces a self-built agent.
Self-built agents have the strength of being easy to observe. You can record each step’s prompts, tool calls, evaluations, and retries yourself. In exchange, you must also bear the responsibility for implementation and operations. Prompt degradation, following model changes, failure recovery, and cost cap management all come to you.
An integrated API can potentially hide much of this burden. However, the hidden parts become harder to observe. So what should be compared is not simple accuracy, but the balance of cost, latency, controllability, observability, and developer experience.
I will verify this while looking at Langfuse traces.
Play after making it observable
When a new model comes out, you immediately want to throw interesting prompts at it. Of course, that is fun in its own right.
However, this time I will deliberately start with observation design. If Fugu’s value lies in “bundling multiple models and roles nicely,” it is better to look not only at the output but also at the changes in observable behavior from the outside.
First, connect as an OpenAI-compatible API, leave traces in Langfuse, and create input sets from Level 1 to Level 3. After that preparation, I will look at actual response quality, speed, cost feel, and variance on rerun.
I am writing this right after subscribing, but this is where the real work begins. Next, I will actually hit the Fugu API and verify what differences are visible on Langfuse.