Pre-Implementation Notes on Vercel's Agent Framework, eve
A summary of my pre-implementation research into Vercel's eve agent framework: directory-based design, the difference between tools and skills, sandboxing, durable execution, and more.

Introduction
I read through the official documentation and release information to evaluate whether eve would fit into my workflow, and I’m leaving my findings here as notes.
The reason I became interested in eve was simple: while designing the Hermes Agent architecture, I was concerned about the cost of building subagent composition, sandboxing, and approval flows from scratch. That’s when I learned that Vercel had released a batteries-included framework. It appeared to address the same challenges I was tackling with Claude Code plugin operations and Langfuse observability design, so I decided to familiarize myself with the specifications first.
I split the initial hands-on verification into a separate article.
VercelのエージェントフレームワークEveをちょっと触ってみた https://llm-lab.dev/posts/vercel-eve-first-look/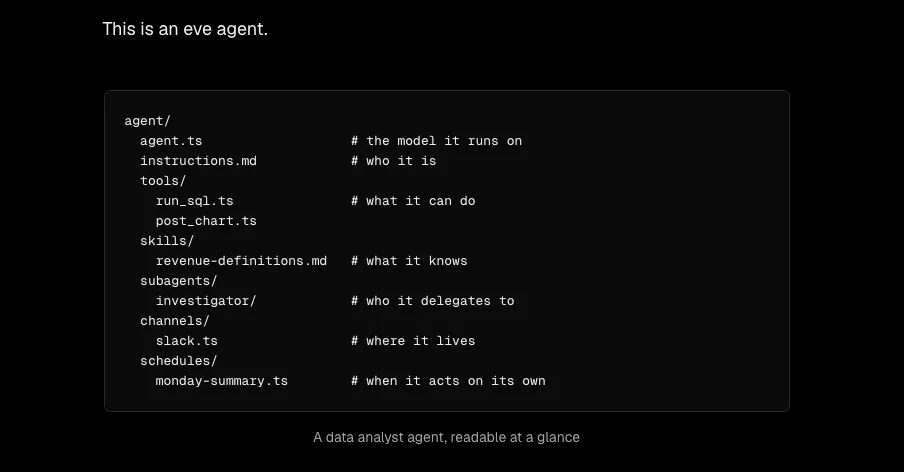
eve’s core philosophy: an agent is a directory
eve’s core lies in the design principle that “an agent is a directory.” The directory structure under agent/ itself defines the agent’s capabilities and identity.
Specifically, the file layout looks like this:
my-agent/
├── agent/
│ ├── agent.ts # runtime config (model selection, etc.)
│ ├── instructions.md # system prompt
│ ├── tools/ # executable actions
│ │ └── get_weather.ts # → becomes the `get_weather` tool
│ ├── skills/ # on-demand knowledge and procedures
│ │ └── summarize.md # → becomes the `summarize` skill
│ ├── connections/ # external connections (MCP, APIs)
│ ├── channels/ # interfaces for Slack, Discord, etc.
│ └── subagents/ # subagents for delegating tasks
└── evals/ # test suiteWhat’s important here is that file placement and names directly define functionality. Dropping agent/tools/get_weather.ts automatically registers it as a get_weather tool without any explicit registry code. This idea is close to Claude Code’s plugin structure and the concept of skills, but eve extends this convention to the entire agent architecture.
This design works because it lets developers focus on “what to make the agent do” rather than “how to run the agent.” It’s a batteries-included approach where session persistence, sandboxing, approval flows, and evaluations—all things you’d normally have to build yourself—come as standard.
Tool vs. skill: the first concept to grasp
As I worked through the docs, the first thing I needed to clarify was the difference between tools and skills. Both are described as “extending the agent’s capabilities,” but they are fundamentally different.
In short, a tool is an “action” and a skill is “knowledge or a procedure.”
| Aspect | Tool | Skill |
|---|---|---|
| Purpose | Execution (drive or manipulate something) | Guidance (teach how or define something) |
| File format | TypeScript (.ts) | Markdown (.md) or TypeScript |
| Invocation timing | When the model decides to execute | Loaded on demand via load_skill |
| Context impact | Description is always present | Body is hidden until loaded |
| Execution environment | Application runtime (inside trust boundary) | Context injection only; no execution capability |
Tools handle concrete operations defined as code, such as API calls or SQL execution. They run in the application runtime, not the sandbox, so they have full access to environment variables and shared libraries.
Skills, on the other hand, are instruction manuals that the model loads on demand using the load_skill tool. Rather than putting all skills into the context at once, only their descriptions are presented upfront, while the full content is lazily loaded. This progressive disclosure design shares the same philosophy as Anthropic’s skills feature, with the common goal of conserving context window space.
The practical distinction documented is: “use a tool when code execution is needed, and a skill when you want to guide the model’s reasoning.” The intended pattern is combining a tool that fetches data from a database with a skill that explains how to interpret that data. This felt continuous with the way I’ve been adjusting prompts while watching traces in Langfuse.
Sandboxing and trust-boundary separation
Another concern was how to safely execute code generated by the agent. In eve, there is a clear separation between the trusted “application runtime” and the “sandbox” where untrusted code runs.
The sandbox cannot access environment variables or application source code. Secrets such as API keys are always held on the application runtime side and are never passed to the sandbox. The sandbox has its own /workspace filesystem and is isolated from the main application.
In production (when deployed to Vercel), it runs on a hardware-isolated Vercel Sandbox (microVM). In local development, it switches to a backend that fits the developer’s environment, such as Docker, microsandbox, or a simple bash process.
For cases requiring network access, there is a “credential brokering” feature that enables secure communication without passing credentials directly into the sandbox. This feels like an out-of-the-box answer to the “where do I put secrets?” question that comes up every time I build a sandbox environment myself.
Durable execution
A quietly annoying part of agent development is state management during long-running tasks or when waiting for human approval. eve manages this through three layers—“session,” “turn,” and “step”—saving checkpoints at each step boundary.
Each turn is executed as a “durable workflow” based on the open-source Workflow SDK (Vercel Workflow when deployed to Vercel). If a process crashes or times out, execution resumes from the last completed step rather than starting over. Completed steps are not re-executed; their recorded results are replayed.
When waiting for human tool approval or a long-running subagent task, the session enters a “parked” state. While parked, the workflow is suspended and consumes no compute resources. Whether seconds or days later, it resumes from where it stopped the instant the required input arrives.
For someone like me who worries about “what happens if the session drops?” during long tasks in Claude Code, this is a compelling feature. That said, I should note this is an unverified impression: the exact step granularity and how compaction interacts with checkpoints were not fully clear from the documentation alone.
Human-in-the-loop implementation
For approval flows, there are two main approaches.
The first is setting a needsApproval field in the tool definition. Helpers are provided: always() (approve every time), once() (only the first time in a session), and never() (no approval, default). You can also write conditional logic to dynamically determine whether approval is needed based on input. For example, you can require approval only when the estimated query cost exceeds a threshold.
The second approach uses the built-in ask_question tool, allowing the agent itself to ask the user for answers via multiple choice or free text. When an approval or question occurs, an input.requested stream event is emitted. Adapters like the Slack adapter automatically render this as buttons or select menus in native UI.
Because approval wait states leverage the durable execution mechanism described earlier, they persist across process restarts and deployments. The approval gate is also designed to prevent accidents where non-idempotent operations like sending emails or billing transactions get replayed and executed twice.
Subagents and dynamic skills
I also looked at the advanced features: subagents and dynamic skills.
Subagents are defined in an independent directory structure under agent/subagents/<name>/. Writing a description in agent.ts is mandatory; the parent agent reads this description to decide which tasks to delegate. Subagents do not inherit the parent’s capabilities and have their own tools/ and skills/. Note that channels/ and schedules/ exist only at the root agent level and are not supported for subagents.
Dynamic skills are a mechanism for switching which skills to provide based on the calling team, tenant, or user permissions. Inside the defineDynamic resolver, you read authentication info or channel metadata and return skills conditionally (or return nothing at all). An example given is serving recruitment guidelines for HR inquiries and coding standards for engineering inquiries. This carries more meaning than simple conditional branching because the very existence of specific skills can be hidden from general users.
Breadth of built-in features
What struck me during the survey was how broad the built-in feature set is. At a glance, it includes:
- Execution & runtime: durable execution, sandboxing, durable state management, compaction, model routing via Vercel AI Gateway
- Human control & observability: approval flows, OpenTelemetry tracing, eval-based scoring tests
- Standard tools: bash, grep, glob, readFile, writeFile, webFetch, webSearch, ask_question, load_skill, todo
- Channels: HTTP API, Slack, Discord, Microsoft Teams, Telegram, Twilio, GitHub, Linear
- Connections: MCP and OpenAPI for Slack, GitHub, Snowflake, Salesforce, Notion, Linear, etc.
- Developer tools: CLI (init/dev/deploy/eval), frontend SDKs for React/Vue/Svelte, integration with Next.js/Nuxt/SvelteKit
Looking at this list, it’s clear that things I’ve previously built myself—trace management in Langfuse, MCP connections, approval flow implementations—are being absorbed into the framework to some extent. On the other hand, deciding how much to use these built-ins versus what to customize is something that only becomes clear after actually working with it.
Mapping it to my workflow
Having read this far, I considered how it might connect with the future architecture of the Hermes Agent.
The subagent design philosophy seems close to the L1/L2/L3 responsibility separation I’m currently considering for the Hermes Agent. In particular, the constraint that subagents do not inherit parent capabilities and must have their own tools/skills seems like a useful reference for explicitly defining responsibility boundaries.
For approval flows, I’ve been implementing something equivalent to needsApproval myself, so having it as a standard feature could save me from reimplementing cost guards and write-protection logic. However, this is still at the “I’ve read the docs” stage—it’s unverified how fine-grained the cost threshold logic can be and how it might interact with external tools like Codex review.
The sandbox trust-boundary separation is a useful reference for the perennial question of how to handle API keys in self-built bots and personal prototyping projects.
Remaining questions and what I want to try next
Let me be honest about what remains unverified.
- How compaction behaves and what step granularity looks like in actual long-running tasks
- Whether MCP connections can coexist with existing Claude Code MCP configurations without conflicts or duplication
- How closely
t.judgein evals aligns with operational review criteria - How much behavioral difference there is between local development (Docker/microsandbox backend) and production (Vercel Sandbox)
As the next step, I plan to start by running eve init to create a small agent and walk through tool, skill, and approval flow functionality. Any stumbling blocks or design decisions from hands-on experience will be covered in a separate article.
Conclusion
This time, I’ve summarized the overview of the eve framework based on documentation alone before implementation. The backbone consists of a file-based design governed by the convention that “an agent is a directory,” the role separation between tools (execution) and skills (knowledge/procedures), a sandbox with separated trust boundaries, and a durable execution model that checkpoints at the step level.
For AI adoption in small-to-medium businesses and personal prototyping, the effort required to build this “plumbing” from scratch often becomes a bottleneck. It’s worth testing how well this batteries-included approach fits. That said, everything here is an organization of official information; the sticking points and limitations from actual implementation are still unknown. I’ll write the follow-up once I’ve built something.


